
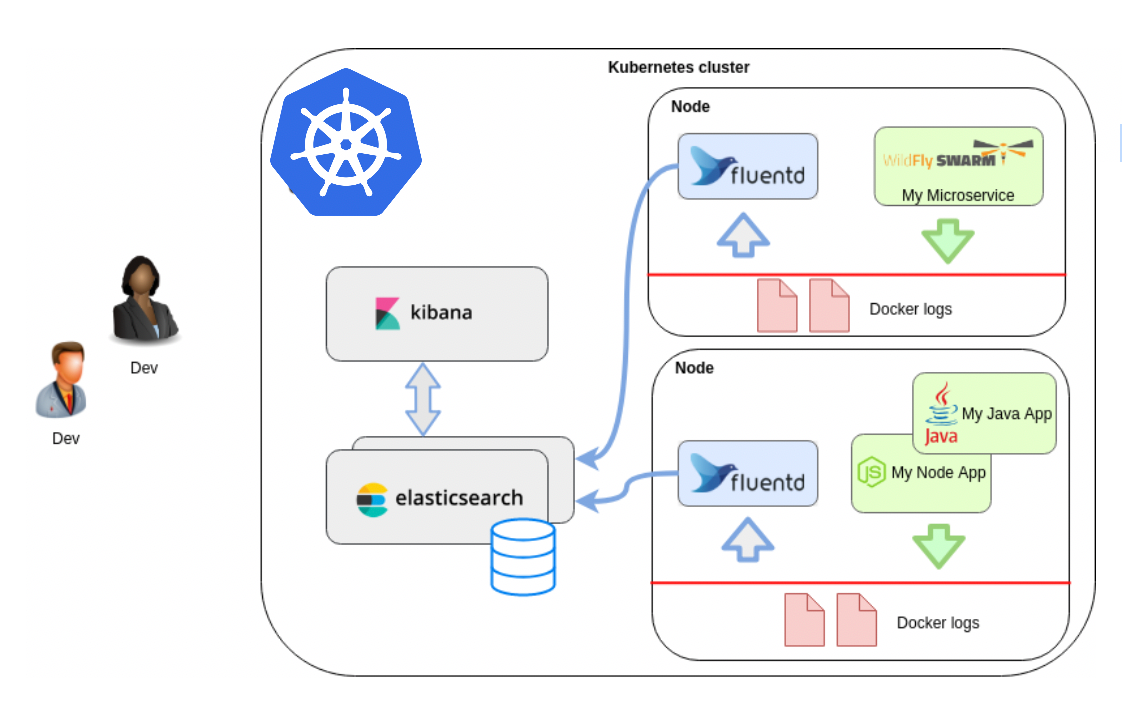
Thanks for going through part-1 of this series, if not go check out that as well here EFK 7.4.0 Stack on Kubernetes. (Part-1). In this part, we will focus on solving our Log collection problem from docker containers inside the cluster. We will do so by deploying fluentd as DaemonSet inside our k8s cluster. DaemonSet ensures that all (or some) nodes run a copy of a pod in all worker nodes of K8s cluster.
In Kubernetes, containerized applications that log to stdout and stderr have their log streams captured and redirected to JSON files on the nodes. The Fluentd Pod will tail these log files, filter log events, transform the log data, and ship it off to the Elasticsearch cluster we deployed earlier.
In addition to container logs, the Fluentd agent will tail Kubernetes system component logs like kubelet, Kube-proxy, and Docker logs. To see a full list of sources tailed by the Fluentd logging agent, consult the kubernetes.conf file used to configure the logging agent.
Step-1 Service Account for Fluentd
First, we will create a Service Account called fluentd that the Fluentd Pods will use to access the Kubernetes API with ClusterRole and ClusterRoleBinding. We create it in the logging Namespace with label app: fluentd.
#fluentd-service-account.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: logging
labels:
app: fluentd
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: fluentd
labels:
app: fluentd
rules:
- apiGroups:
- "*"
resources:
- pods
- namespaces
verbs:
- get
- list
- watch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: fluentd
roleRef:
kind: ClusterRole
name: fluentd
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: fluentd
namespace: logging
Step-2 Fluent Configuration as ConfigMap
Secondly, we’ll create a configMap fluentd-configmap,to provide a config file to our fluentd daemonset with all the required properties.
Here, we will be creating a “separate index for each namespace” to isolate the different environments. Optionally, user can create the index as per the different pods name as well in the K8s cluster.
Also, we will see how to “disable the index creation for certain namespaces & pods.”
#fluetd-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-configmap
namespace: logging
labels:
app: fluentd
kubernetes.io/cluster-service: "true"
data:
fluent.conf: |
<match fluent.**>
@type null
</match>
<source>
@type tail
path /var/log/containers/*.log
# Here in exclude_path, we can define the path having the namespace name like prometheus, logging etc for which we don't want to create the indexes.
exclude_path ["/var/log/containers/*prometheus*.log", "/var/log/containers/*logging*.log"]
pos_file /var/log/fluentd-containers.log.pos
time_format %Y-%m-%dT%H:%M:%S.%NZ
tag kubernetes.*
format json
read_from_head false
</source>
<filter kubernetes.**>
@type kubernetes_metadata
verify_ssl false
</filter>
<match kubernetes.**>
@type elasticsearch_dynamic
include_tag_key true
logstash_format true
#Below line is use to isolate the indexes as per different namespaces in K8s.
logstash_prefix kubernetes-${record['kubernetes']['namespace_name']}
#Uncomment the below line, if want to isolate the indexes as per different pods in K8s.
#logstash_prefix kubernetes-${record['kubernetes']['pod_name']}
host "#{ENV['FLUENT_ELASTICSEARCH_HOST']}"
port "#{ENV['FLUENT_ELASTICSEARCH_PORT']}"
scheme "#{ENV['FLUENT_ELASTICSEARCH_SCHEME'] || 'http'}"
user "#{ENV['FLUENT_ELASTICSEARCH_USER']}"
password "#{ENV['FLUENT_ELASTICSEARCH_PASSWORD']}"
reload_connections false
reconnect_on_error true
reload_on_failure true
<buffer>
flush_thread_count 16
flush_interval 5s
chunk_limit_size 2M
queue_limit_length 32
retry_max_interval 30
retry_forever true
</buffer>
</matchΩ
Step-3 Fluentd as Daemonset
Now, we will deploy Fluentd as DaemonSet which allows to deploy an agent on each node of the k8s cluster to collect logs according to the settings configured in Step-2.
#fluentd-daemonset.yaml
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: fluentd
namespace: logging
labels:
app: fluentd
kubernetes.io/cluster-service: "true"
spec:
selector:
matchLabels:
app: fluentd
kubernetes.io/cluster-service: "true"
template:
metadata:
labels:
app: fluentd
kubernetes.io/cluster-service: "true"
spec:
serviceAccount: fluentd
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.7.3-debian-elasticsearch7-1.0
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch.logging.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENT_ELASTICSEARCH_USER
value: "elastic"
- name: FLUENT_ELASTICSEARCH_PASSWORD
valueFrom:
secretKeyRef:
name: efk-pw-elastic
key: password
- name: FLUENT_ELASTICSEARCH_SED_DISABLE
value: "true"
resources:
limits:
memory: 512Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: fluentconfig
mountPath: /fluentd/etc/fluent.conf
subPath: fluent.conf
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: fluentconfig
configMap:
name: fluentdconf
Step-4 Apply the files & see indexes in Kibana
We will apply all the configured files as below
kubectl apply -f fluentd-service-account.yaml \
-f fluentd-configmap.yaml \
-f fluentd-daemonset.yaml
Now, Open the Kibana Dashboard with admin user created in Part-1 and navigate to Management from Left bar and then click on Index management under Elasticsearch. Here you can see your indexes created with respect to the different namespaces in the K8s cluster.
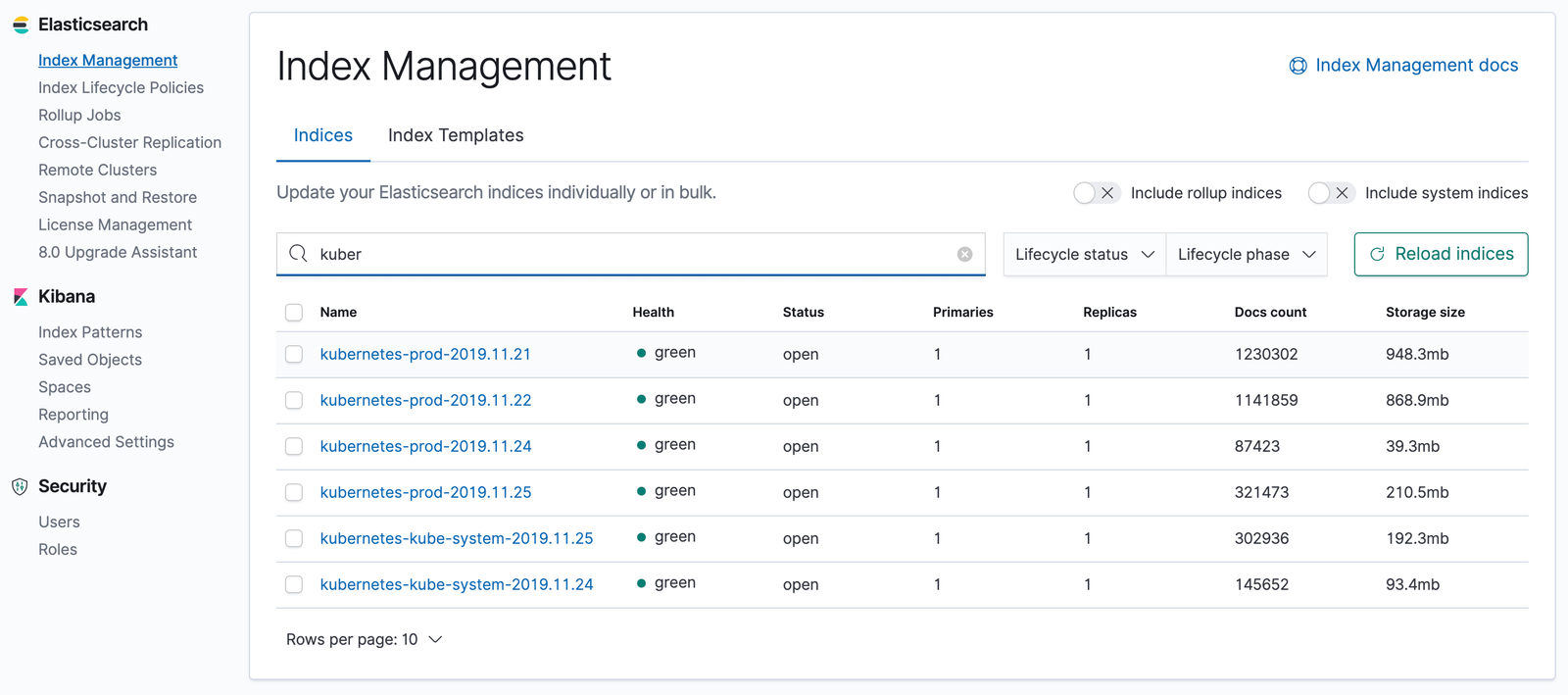
Here, I am having indexes for 2 namespaces i.e. prod & Kube-system, rest others I have disabled.


