
Why DevOps Rides on Immutable Infrastructure? The acceptance of “immutable infrastructure” has emerged as a viable way to improve DevOps processes and culture. By introducing standardisation in application deployment and management, the immutable infrastructure helps, among other things, to foster a better collaborative environment among developers, operations, and other stakeholders.
Let’s discuss a bit about Immutable Infra and the benefits which it brings to the table. Once we have a better understanding of it, we’ll really start to see the use case in our Deployments Model.
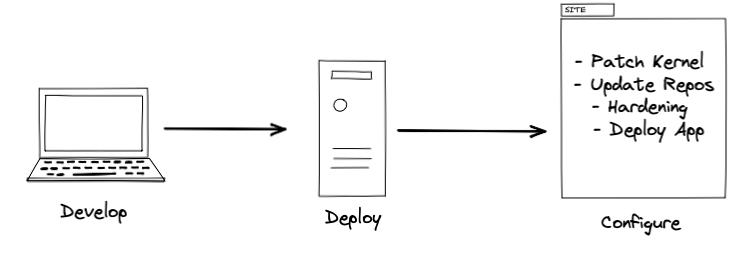
Mutable Flow :
Immutable Flow :
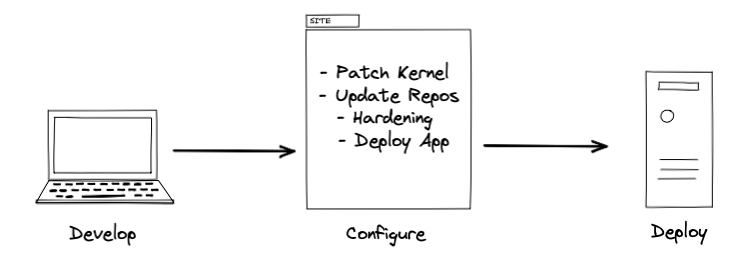
The difference is, when we go immutable, we don’t want to ever upgrade in place as we do in Mutable. An immutable infrastructure is another infrastructure model in which servers are never modified after they’re deployed. If something needs to be updated, fixed, or modified in any way, new servers built from a custom machine images with the appropriate changes are provisioned to replace the old ones. And, here comes Packer to create those customized machine images to fit for our need.
Packer
Is an open source tool which allows us to create custom identical machine images for multiple platforms from a single source configuration.
Packer Template Workflow :
Builders: Are responsible for creating machines and generating images from them for various platforms.
Provisioners: Use builtin and third-party software to install and configure the machine image after booting.
Post-processors: Are optional, and they can be used to upload artifacts, or to generate outputs of the artifacts build or generated.

What’s in the Project
In this project, we will be baking an AMI using Packer, handling configuration with Bash Script during the baking process to host a static website. We need to make sure nginx is enabled in systemctl and starts on every boot so it is ready to process immediately. And, using Terraform we gonna provision our servers, followed by software release deployment strategies to check and test our infra model.
The essence is, we will be deploying two versions of our code with two different machine images V1 and V2 to see the purpose of Immutable Infrastructure with Re-Create deployment strategy.
Step 1 : Setup Packer Template to Generate the AMI
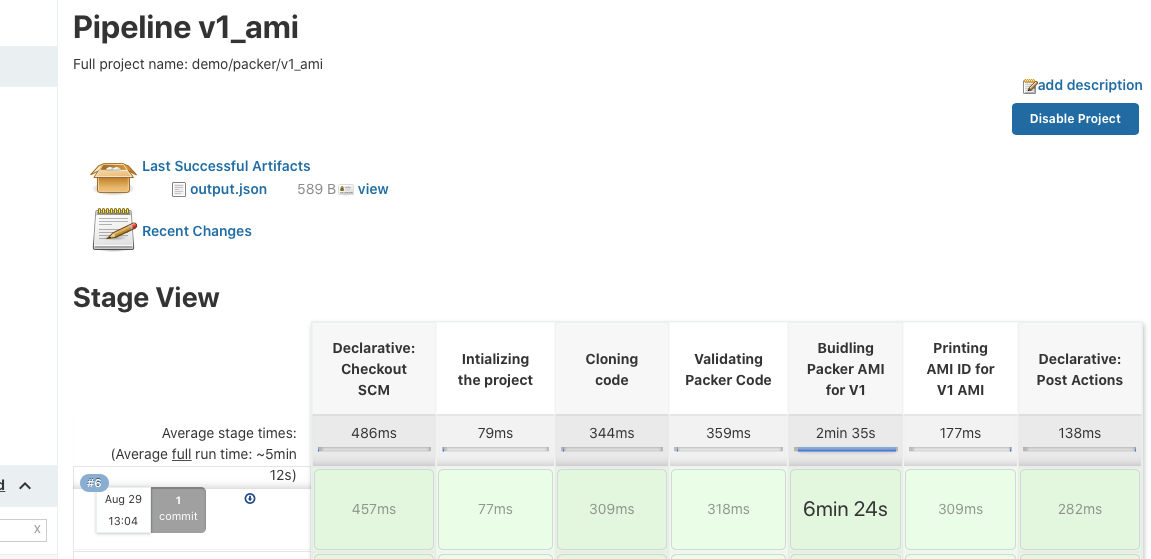
In this step, we are going to create a Packer Template with the use of Builders for AWS Platform to create AMI, using Bash Script as Provisioners to configure our machine with the static website page and the restart of our Nginx Service. And, Post-processors as Manifest type to generate the output.json file to get our AMI ID.
The template code can be found here. We will be using Jenkins to build the image, the Jenkins file is kept with the code itself. And we will be getting the output.json file as a post-processing step giving us the AMI ID.

Step 2 : Setup Terraform to Provision and Deploy our Infra using above AMI‘s
In this step, we are going to create Terraform manifests to provision our Infra by creating an Application Load Balancer and, Auto-Scaling Group using Launched Template, in our case will be making use of default network system of AWS account.
The manifest code can be found here. The AMI ID is passed to the Launched Template using vars.tf to provision and deploy our V1 Application. To run this code we have another Jenkins Pipeline job which registers the provisioned computes under the Load Balancer and their desired capacity is managed by ASG.
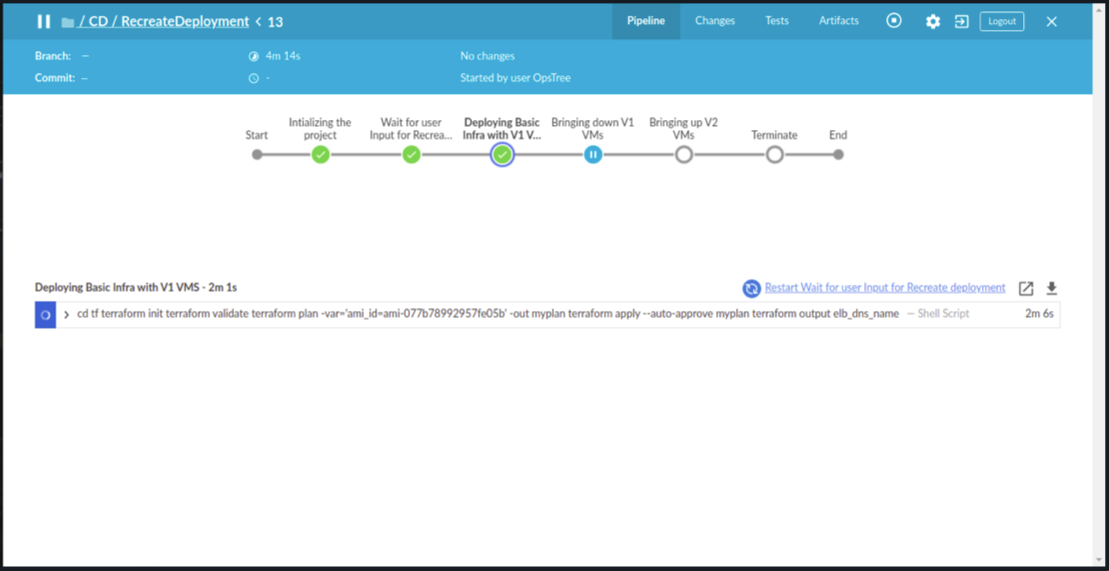
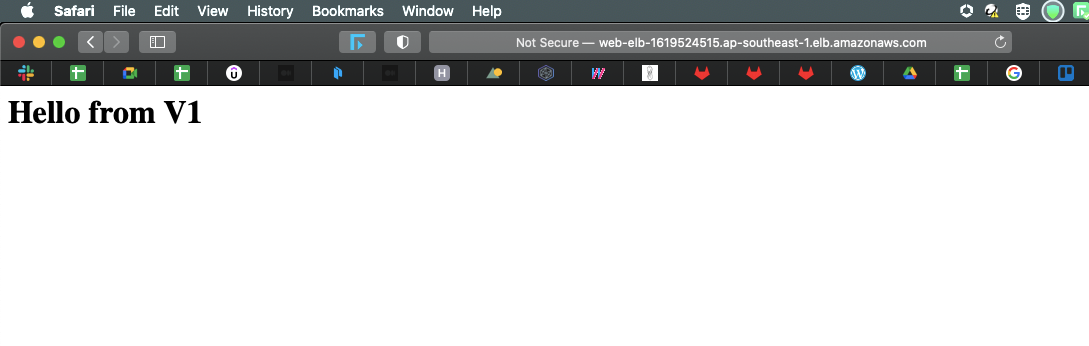
If we follow the Pipeline, we have deployed the Basic Infra of our V1 application which can be accessed by the endpoint provided by the Application Load Balancer.
TADA !! Our V1 Application is Ready 🙂
As we mentioned above we will be following the Re-Create Deployment Strategy which states: deployment consists of shutting down V1 then deploying V2 after V1 is turned off. If we follow the Continuous Delivery pipeline of deploying Infra then we will see that it asks for a manual approval of shutting down the V1 infra and deploying the V2 infra, besides V1 AMI we did created our V2 AMI as well at the same time.
And, once we proceed with the approval of shutting down our V1 Infra, it brings the change to desired capacity of computes to zero for our ASG configuration as follows :
stage('Bringing down V1 VMs') {
input {
message "Shall we bring down V1 VM's?"
ok "Yes, we should."
}
steps {
sh '''
cd cd/tf
terraform init
terraform validate
terraform plan -var='ami_id=ami-xxxxx' -var='min_capacity=0' -var='desired_capacity=0' -out myplan
terraform apply --auto-approve myplan
'''
}
}
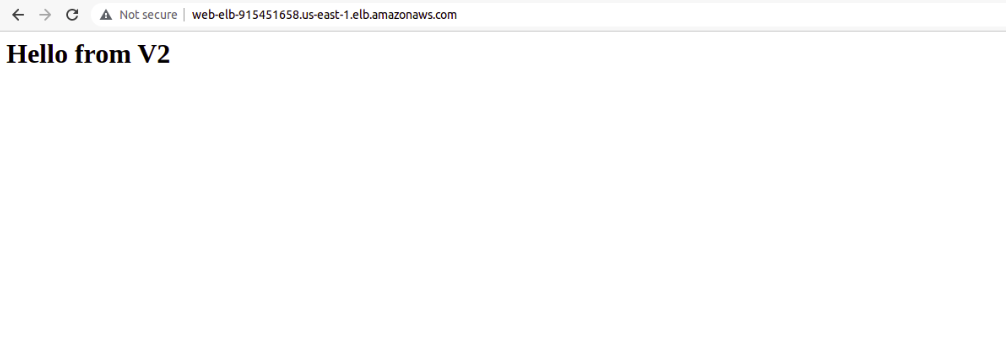
Which deletes the infra of V1 and then start deploying the V2 and register these computes behind our Load Balancer which can be accessed and given O/P as
TADA !! V2 Application Up and Running 🙂
Conclusion
In this blog we have uncovered how Packer and Terraform can remarkably reduce the overhead of revising the pre-configured golden AMIs by the means of IAAC helping us incorporate the entire provisioning in our CI/CD pipelines empowering the immutable infrastructures.
Bonus : The way we had introduced the Re-create strategy over the post, we have implemented for Rolling Strategy as well. Do give it a try and share your experience with us in the comment box.
Till then Keep Deploying 🙂
Blog Pundit: Adeel Ahmad and Naveen Verma
Opstree is an End to End DevOps solution provider
Connect Us