
Introduction
There are different application categories in the general application world, but we usually define them in two major types, i.e., stateless and stateful applications. In Kubernetes, this distinction becomes especially important when designing and managing workloads.
To have a clearer perspective, we can say that API-based applications are generally stateless, and databases are stateful. In simple words or definition, a stateless application is an application that doesn’t save or persists the client data. On the other hand, a stateful application saves data about each client and uses it for other requests.
In the older days, when we didn’t have a concept of containers and container orchestrators, there was a common way to manage both types of applications: server. For example- API and database-based applications get hosted on servers but with different configurations depending on the resource requirements.
But we don’t hesitate to say this now, as we live in a microservices era, where organizations are bundling their application in containers and using an orchestrator to manage them. For stateless applications, the management is significantly less, but now people want to shift stateful applications to container orchestrators like – Kubernetes and ECS.
Since Kubernetes is becoming a buzzword in the technical community, let’s discuss it more. There are different easy ways to manage stateless applications inside Kubernetes clusters like – Deployment, DaemonSet, etc. To manage stateful-based applications inside Kubernetes, we can use Deployment, DaemonSet, and Statefulset, but all these depend on one common resource: Persistent Volume.
As we know, pods are ephemeral, which means no data will be saved if a pod is restarted or deleted. Still, in the case of databases or critical stateful applications, we also need to persist data after the restart. In a nutshell, Persistent Volumes are block or shared volumes that generally get mounted to containers inside the pod so that the container can write the persistent data on it.
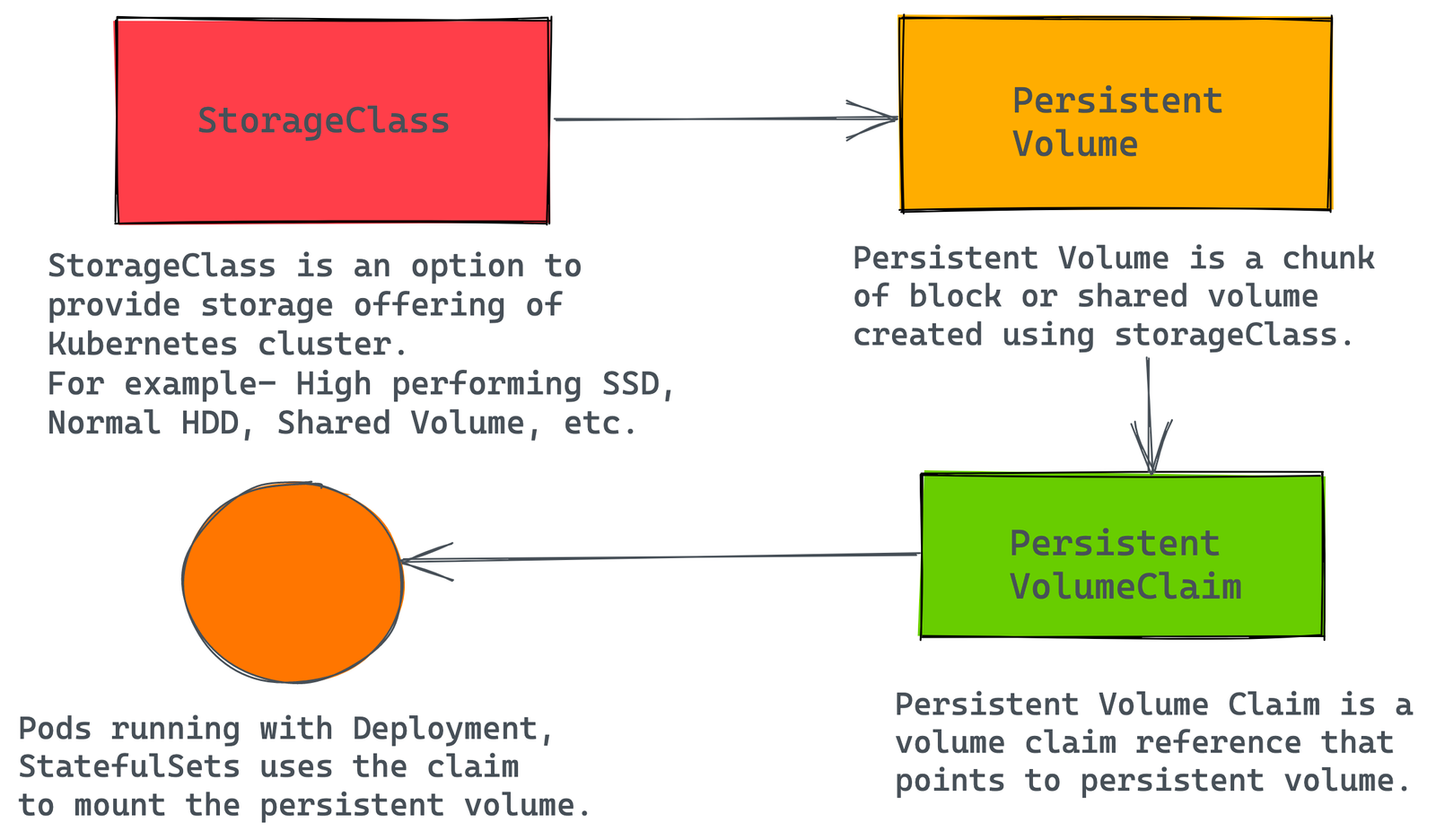
The journey of Persistent Volume:-
What is Container Storage Interface?
While working on managed services of Kubernetes like- EKS, AKS, or GKE, whenever we create a persistent volume, there is already a default storage class available. Generally, people don’t ask this question from where precisely these storage classes are coming. And how is it integrated with the cloud? i.e., whenever we create a persistent volume, an actual volume is created inside the cloud as block or shared storage.
But I got an opportunity to work with a banking company, and they had an on-premises setup of Kubernetes on which they were already running the stateless applications. Still, they wanted to migrate a few non-critical stateful applications to the Kubernetes cluster to leverage its features and functionality. We already had a storage class available if the application was cloud hosted. We won’t think or blink in migrating the application to Kubernetes. Still, there was no storage class in this case because everything was running on a local data center.
Here the challenge becomes interesting because managing a stateful application in cloud Kubernetes is easy. Yet, for the same stateful application in on-prem Kubernetes, we need to do several things to make it work.
The CSI (Container Storage Interface) comes into place to solve such challenges and scenarios. CSI is a standard way of exposing the storage systems to the containerized workload on container orchestration platforms like- Kubernetes, Mesos, and Nomad. It is a critical component in integrating third-party storage services like- Ceph, GlusterFS, and NFS into storage systems of orchestration platforms.
Why Container Storage Interface?
One of the main reasons for Kubernetes’ popularity is that it provides an extension where people can develop and plug their features. In network extensibility, we have different overlay network drivers available, like – Flannel, Calico, and Weavenet, which can be integrated into the Kubernetes network.
Similarly, CSI provides the capability inside Kubernetes to integrate different storage drivers like- Ceph, GlusterFS, and NFS. Even the managed cloud-based Kubernetes also uses the concept of CSI to integrate their storage services to Kubernetes or other orchestrators. Before the idea of CSI, the storage providers had to contribute the integration code of their storage services inside the Kubernetes codebases. They had to do the same re-development for other orchestrators like Nomad, Mesos, etc.
For standardizing the storage services for different container workloads, the concept of CSI has been created through which any storage provider has to write a generic plugin driver, which can be integrated into the different orchestration platforms.
For the list of CSI drivers, please refer to the official site of Kubernetes:
https://kubernetes-csi.github.io/docs/drivers.html
Conclusion
This blog explains the concept and needs for the Container Storage Interface(CSI) and how it solves different stateful application hosting issues on container orchestrators. In the next part of the blog, we will discuss the integration of the on-prem Ceph cluster to the Kubernetes cluster using CSI.
Please comment in the comment section if you have any other ideas or suggestions about the approach. Thanks for reading. I’d appreciate your suggestions and feedback.


