
We often face complications after a certain point when we can not change the foundation layer of our code because we haven’t thought it through and didn’t plan or strategize the way of writing code in the beginning, there are certain points which should be taken under consideration similarly there are some common mistakes which we should avoid.
After managing numerous Infrastructures as a code with a plethora of terraform modules, We at Opstree have build up a decent maturity with Terraform and have a defined workflow with best practices. In this blog post, I will be sharing the learning which I acquired using Terraform for diverse Infrastructures.
Versioning with Git
Version control is the essential requirement to keep track of every change to a file over time so early versions can be restored and are used by your teams for source code.
Ensure that you have a proper .gitignore, .env, README.md files in your repositories.
.gitignore: Mention the files which you want to ignore, in this case, it could be.env,*.tfstate.*files and,.terraformdirectory..env: In this file, you can manage your environment variables going to be used in the code.README.md: It is an essential part of the code which has the document of usage of the code, it helps the user to get a proper understanding of the code also it helps in easy onboarding of new members in the team.CHANGELOG.md: In the case of Terraform modules one should maintain a proper release history with CHANGELOG.md.
Backend got your back
Whenever you run terraform to create or update your infrastructure it stores the state of resource it has created in a readable JSON file. Which has a mapping of your resources present in the .tf files of your code.
If you are using terraform individually then keeping the state file in local could be agreeable, but it has it’s own drawbacks like if your system underwent failure then your state will be lost and there is no way getting it back. Also if managing Terraform among large teams you want to keep it at a sharable space. That sharable space must have functionalities like:
- Regular update: We want the state files to be updated automatically whenever a change takes place to avoid any manual error.
- Locking: The state files need to be locked when two or more people are simultaneously running terraform on the same state file.
- Encryption: The state file consists of a lot of secrets related to the infrastructure which can not be exposed.
Clearly a VCS is not a wise choice to keep the state files considering the above requirements. Hence terraform has its own functionality called remote backends to store the state files. The below snippet of creating an s3 bucket will do the needful for using it as a backend.
resource "aws_s3_bucket" "terraform_state" {
bucket = "terraform-up-and-running-state"
# Enable versioning of state files
versioning {
enabled = true
}
# To prevent deletion of the S3 bucket
lifecycle {
prevent_destroy = true
}
# To enable server-side encryption by default
server_side_encryption_configuration {
rule {
apply_server_side_encryption_by_default {
sse_algorithm = "AES256"
}
}
}
}
Logical separation of components
Let us consider an example in which we’ll be creating various components of an Infrastructure
- Networking Segment in which we’ll be creating various resources in our infrastructure like VPC, IGW, Subnets, NAT, NACL, Route tables, etc which we can entitle as a networking segment of our Infrastructure.
- A Highly available frontend application, for that we’ll be creating resources like Route53 record, Load balancers, Launch templates, Autoscaling groups, EC2 instances, Security Groups, etc.
- Backend services, Databases, Middleware, and so on…
Considering the above examples if we want to cause a change in the frontend application then we need not worry about the networking segment because the code of both segments is already separated and are independent of the changes happening among them. So categorizing the code will be beneficial for hassle-free management of resources.
Hierarchy in module: child, parent !!
It is an unsaid rule in development that if we are using a chunk of code repeatedly, then create a function of it and call it whenever needed. A similar approach is well-liked in terraform called Modules.
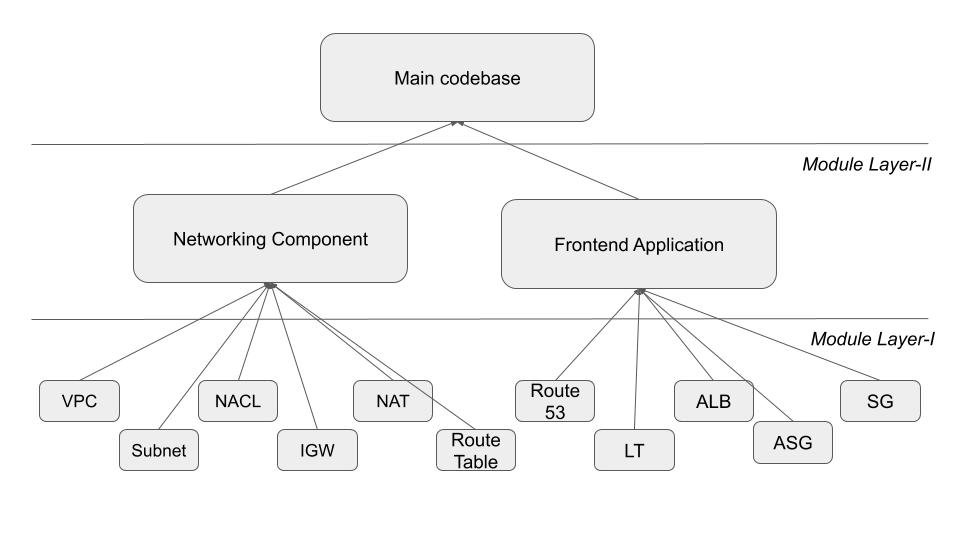
In the above diagram you can see multiple layers used to create modules, let me explain the significance of each layer.
- Module Layer-I: In this layer, we have modules of each and every resource which is going to be used in the bigger scheme of creating infra. You conclude is as the building block of our infrastructure as suggested in the below-mentioned snippet.
# Layer-I
$ cat vpc.tf
resource "aws_vpc" "main" {
......
}
$ cat subnet.tf
resource "aws_subnet" "subnet_1" {
....
}
- Module Layer-II: In this layer, we have our customized modules with respect to the use-cases, for eg: to have networking in place, the layer-II networking component will be calling the modules from layer-I, the below code snippet will give better clarity.
$ cat network_component.tf
# Layer-II Network Component
module "vpc" {
source = "Layer-I/vpc"
.....
}
module "subnet" {
source = "Layer-I/subnet"
.....
}
......
Proper usage of variables
Terraform has it’s own variable precedence as mentioned in below figure.

As you can see there are various ways to define variables in terraform depending upon the use cases, there are a couple of practices that can be followed to improve the way we define variables.
- Locals: If there are some values whose values are kept to be constant try not putting them as variables define them as local, moreover you can create functions or ternary operators and use the resulting values in a couple of places, as shown in below snippet.
locals {
public_dir_with_leading_slash = "${length(var.public_dir) > 0 ? "/${var.public_dir}" : ""}"
static_website_routing_rules = <<EOF
[{
"Condition": {
"KeyPrefixEquals": "${var.public_dir}/${var.public_dir}/"
},
"Redirect": {
"Protocol": "https",
"HostName": "${var.domain_name}",
"ReplaceKeyPrefixWith": "",
"HttpRedirectCode": "301"
}
}]
EOF
}
data "aws_iam_policy_document" "static_website_read_with_secret" {
statement {
sid = "1"
actions = ["s3:GetObject"]
resources = ["${aws_s3_bucket.static_website.arn}${local.public_dir_with_leading_slash}/*"]
.....
}
- Validation: A set of validation can be incorporated while defining the variable so that to enforce the user to inject the specific syntactical value for eg: we know the AMI id syntax in AWS, so to ensure the input value to be such we can use below snippet.
variable "image_id" {
type = string
description = "The id of the machine image (AMI) to use for the server."
validation {
# regex(...) fails if it cannot find a match
condition = can(regex("^ami-", var.image_id))
error_message = "The image_id value must be a valid AMI id, starting with \"ami-\"."
}
}
Secrets better kept as secrets
We are well aware that terraform makes API calls to the cloud provider, hence it needs authentication and authoriZation to make any changes. This is done by using secret access keys provided by the provider, these secret access keys supposed to be used in a way so that they should not be a part of your code. As we say DO NOT COMMIT SECRETS IN VCS.
Hence there are a couple of ways you can manage your secrets access keys.
- Environment file(
.env): We can keep our secret access keys in.envand mention this file in.gitignoreto avoid havoc.
$. cat .env
unset "${!TF_VAR_@}"
export TF_VAR_aws_access_key_id=*****************
export TF_VAR_aws_secret_access_key=**************
$. cat main.tf
provider "aws" {
region = "us-west-2"
access_key = var.aws_access_key_id
secret_key = var.aws_secret_access_key
}
- Using Shared credentials file: The better way that the above to have secrets in a file outside the code directory The default location is
$HOME/.aws/credentialson Linux and OS X, or"%USERPROFILE%\.aws\credentials"
$ cat /Users/tf_user/.aws/creds
[customprofile]
aws_access_key_id = ******************
aws_secret_access_key = *****************
$ cat main.tf
provider "aws" {
region = "us-west-2"
shared_credentials_file = "/Users/tf_user/.aws/creds"
profile = "customprofile"
}
Another secret could be of your aws_db_instance the password which can be randomly generated and it’s output can also be encrypted as shown in the below example.
$ cat main.tf
# Password generator
resource "random_password" "postgres_admin_password" {
length = 26
special = false
}
resource "aws_db_instance" "default" {
identifier = var.name
...
...
password = random_password.postgres_admin_password.result
}
$ cat output.tf
output "db_password" {
value = aws_db_instance.db.password
description = "The password for logging in to the database."
sensitive = true
}
The sensitive flag in the output code will encrypt the password and can be further used in the rest of the code.
In the next part of this blog, I’ll be explaining how to use terraform in a team at a scale with appropriate automation and workflow. Stay tuned!!!
If you got any feedback or queries regarding the blog please leave your comment below I’d really appreciate it.
Thank you for reading 🙂


