
As promised in our previous blog on Redis Performance tunning and Best practices, we have explored more best practices and optimizations in Redis as a cache and database management system. This blog will share some new findings and optimizations we learned in our previous blog’s delta period.
We know that Redis is a high-speed and flexible data storage that can fulfill different cache and database requirements. But if a system is not configured and tested correctly, even a fast and reliable one can quickly become limited. Here we will talk about the different needs of Redis as a system and how we can optimize it further to fully use it.
So while consulting and collaborating with different Redis architects from Redis Labs, I learned different ways of designing a performance-grade, highly available, and secure Redis architecture. Based on my learning, I would like to categorize it into these dimensions:-
- Right-sizing and deployment of Redis setup.
- Proxy and connection pooling.
- Use the correct data type for storing keys.
- Sharding and replication strategy.
Right-sizing and deployment of Redis setup
To define the correct sizing and deployment model for Redis, we must first analyze the application’s workload and data access pattern. This insight will help determine the required memory capacity, CPU resources, and network bandwidth. Redis provides different types of deployment models:
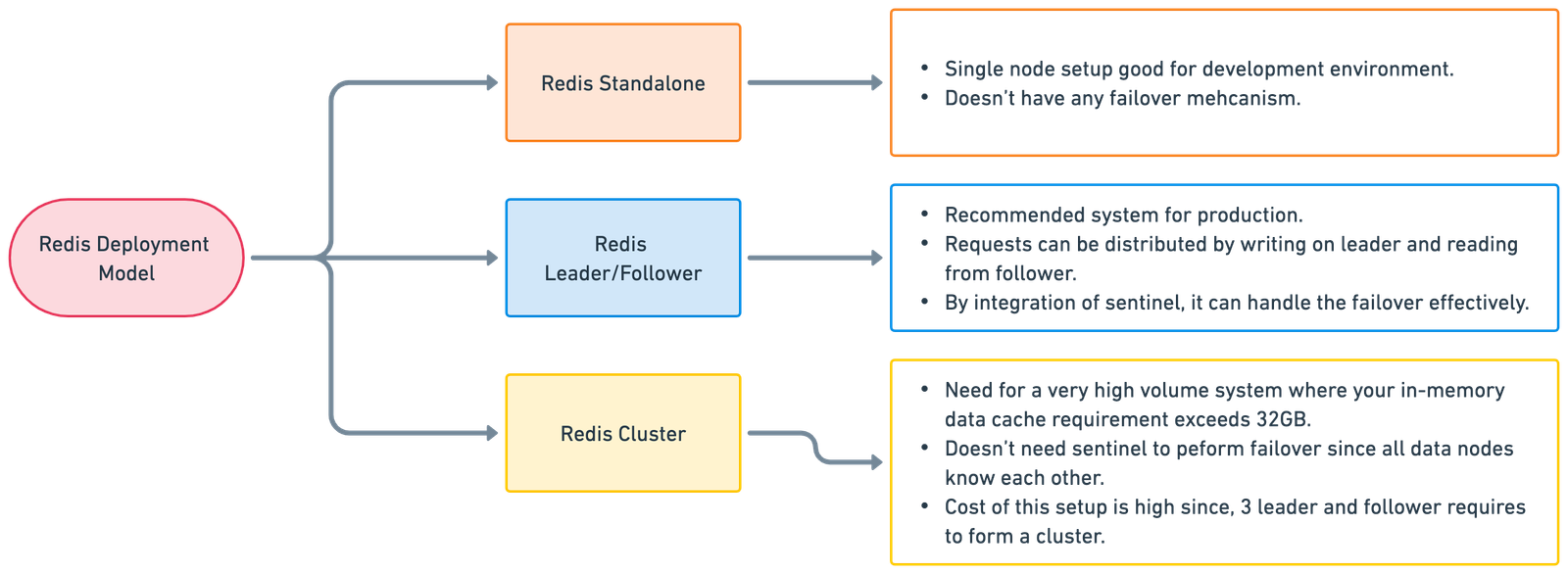
In the above flow diagram, we have explained that each deployment model has a specific purpose and, accordingly, should be chosen. For example, suppose we run our workloads in production that require< 32GB of cache in memory. In that case, we can opt for Redis Leader/Follower architecture instead of Redis Cluster because the Redis Cluster cluster will increase your infrastructure and operations costs.
Proxy and Connection Pooling in Redis
Redis has a feature called “pipeline.” This feature allows a redis client to send different redis commands in an asynchronous method and read their response as a single outcome. Most of the proxy solutions provide connection pooling so that we don’t have to make a connection every time with the system.
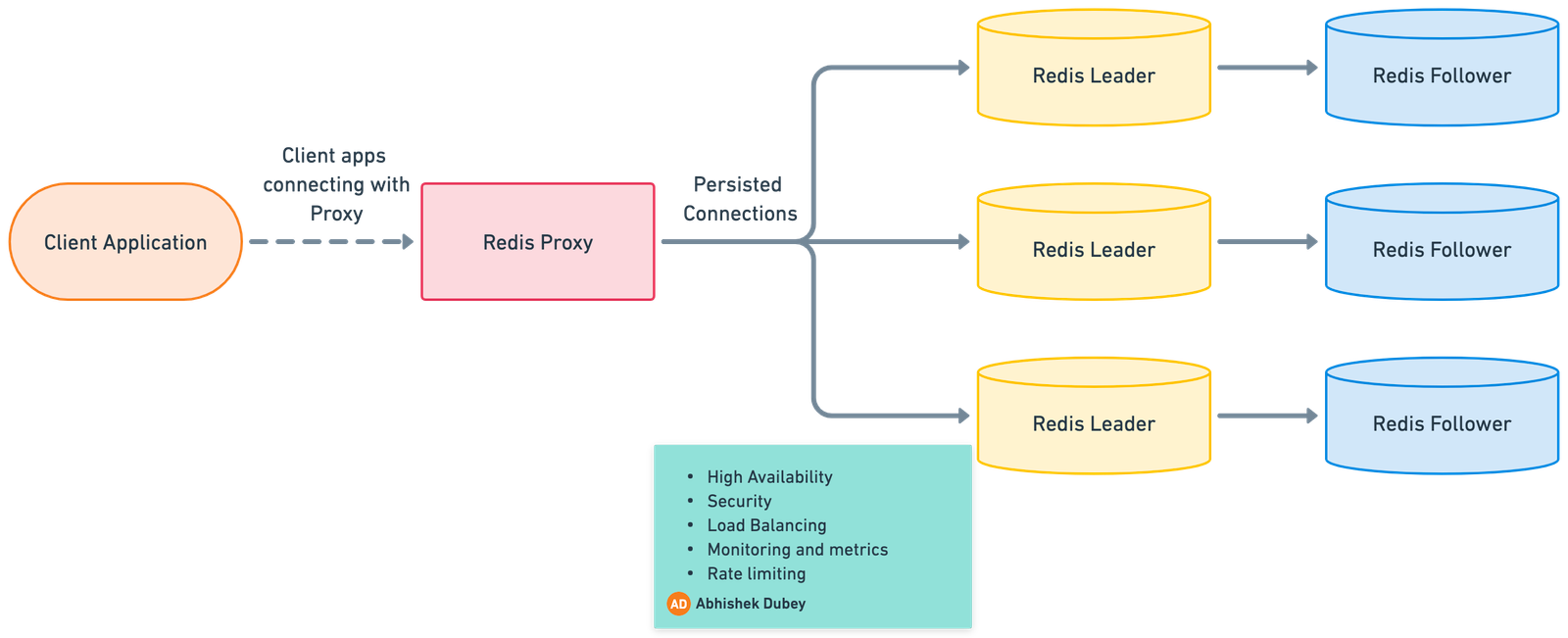
Also, one more significant benefit of using the proxy with Redis is that some SDKs, like .Net core, etc., don’t allow you to provide multiple endpoints in case of a Redis cluster. But a single endpoint can become a single point of failure. To overcome such issues proxy can be introduced because it will only send the requests to healthy Redis nodes like a Load Balancer.
Some other benefits of using a proxy with Redis are:-
- High Availability
- Security
- Load Balancing
- Monitoring and metrics
- Rate limiting
A few famous examples of Redis-supported proxies are the Envoy proxy and Twemproxy.
The correct Data type for storing keys
Again we have to comprehensively analyze our workload before defining the data type of keys. Redis supports different data types for storing the keys, such as:
- String
- Hash
- List
- Set
- Streams etc.
Each data type has different benefits and drawbacks. For example, choosing hash over string gives different advantages. Access/updating/deleting individual JSON fields on hashes is more accessible than the strings. We don’t have to get the whole string, decode, make changes, and set it again.
If the size of your string object increases, we will suffer from network and bandwidth while transferring(get/set) the whole object, whereas it’s far more performant in the case of hashes. Hashes are more memory friendly than strings if you make an excellent benchmark to design your data size. As it is stated in the documentation.
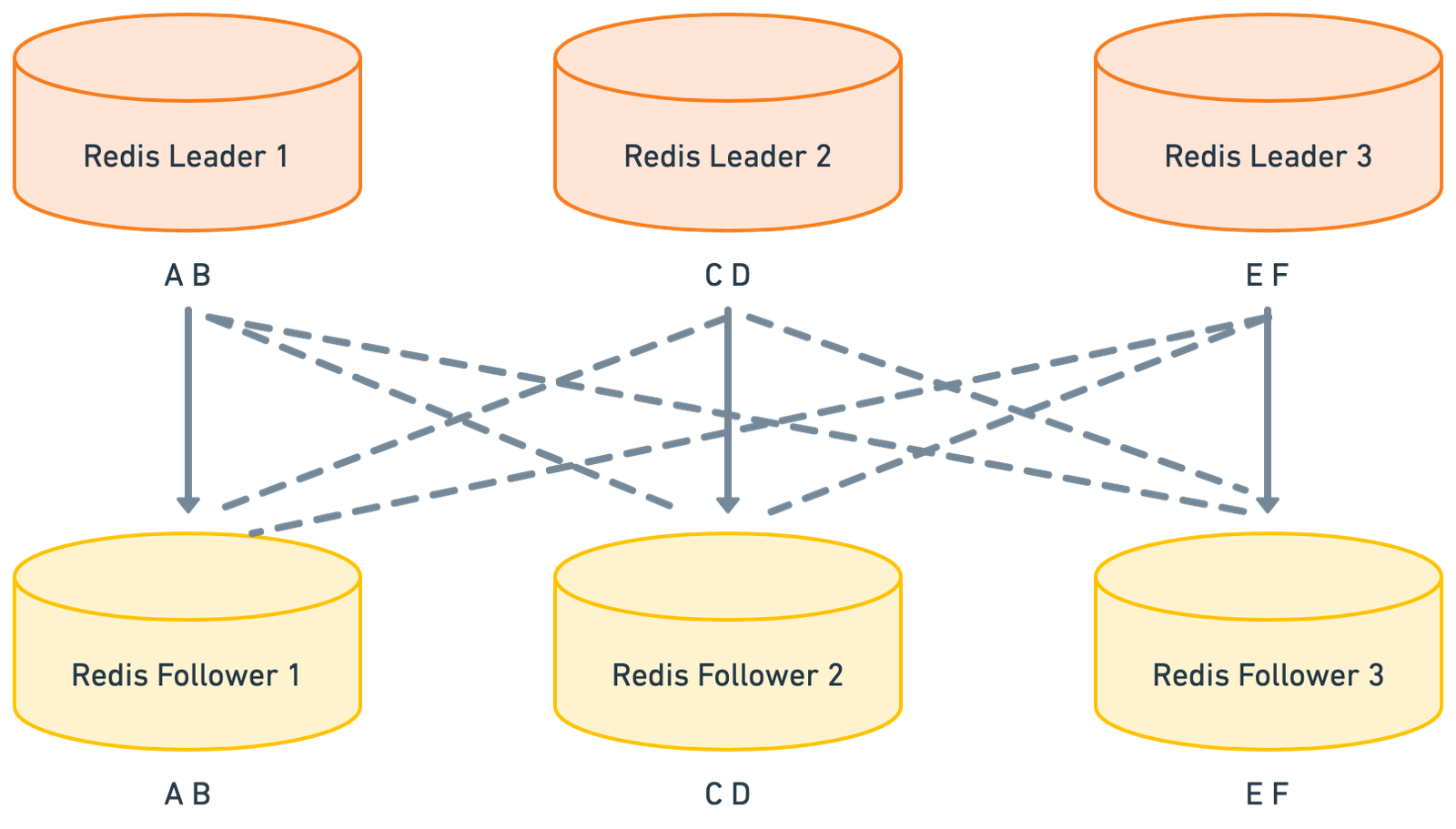
Sharding and Replication strategy
In the Redis setup, we can use deployment models like replication, sharding, and replication + sharding. By default, these configurations are set to manage the low-scale data size. If we want to use Redis as a database system, we may need to further optimize these configurations. For example, the number of replicas should not exceed the number of followers. Otherwise, it will impact the performance of Redis.
Also, Redis, by default, store the hash slot with 64 bytes of compressed data, which is too low. An ideal number of redis slot sizes can go up to 25GB, which can improve the performance of Redis by not creating too many hashes for few amount of data.
Conclusion
So in this blog, we talked about optimizing Redis at different levels, like the operations side, which includes setup and management, and the development side, where the data insertion and structure should be managed. And that’s how an ideal optimization strategy works: optimization at every layer, including development, operations, security, etc.
I hope you guys enjoyed reading the blog. I will explore other features and optimization on Redis that can become part of our future blog series. If you have any feedback or suggestions, please comment on the blog.
Till next time, Cheers!
Blog Pundits: Sandeep Rawat
OpsTree is an End-to-End DevOps Solution Provider.
Connect with Us


