
Enterprises need multiple things to run their business successfully. One of the critical things is the data store they use for storing the data that applications and different analytics platforms will use. To ensure that business is healthy, companies need reliable databases, and according to their tech budget and expertise, they choose databases.
While working and consulting with an enterprise, they ran Cassandra to support their NoSQL data-store operations. Cassandra was working really well but now when the company grew, they needed help to support the NoSQL store. They experienced cascading latencies by Cassandra Hot’s partition as the traffic increased with the events and campaigns. Also, garbage collection was becoming the bottleneck because it heavily impacted the database performance, resulting in poor application performance. Also, one more significant reason was that they wanted to avoid managing the database and were looking for an expert company that could manage it for them without significant application changes.
Why ScyllaDB?
While exploring the different solutions for the database, ScyllaDB caught our attention. We were curious about the solution and did multiple proofs of concept on the ScyllaDB. We finally decided this would be the right choice for our environment and scale. A few primary reasons for our decision were:
- We observed a significant performance increase of 4X with the same data size we are storing in Cassandra.
- Our computing infrastructure was reduced, so we didn’t need to run the number of nodes equal to the Cassandra cluster. With a smaller ScyllaDB cluster, we achieved high performance.
- We leveraged the component of ScyllaDB manager, and it helped in our administration work with the databases, like incremental backup and optimizing the computing infrastructure.
- One significant reason was the scalable nature of ScyllaDB. We tested our application by scaling the ScyllaDB cluster horizontally and vertically.
- ScyllaDB is written in C programming language, so we didn’t have to worry about the garbage collection and its performance impact.
- Since we were already using Cassandra, we didn’t have to make any driver or schema-level changes for migrating to the ScyllaDB cluster.
- Our overall RTO and RPO were improved due to the data-store efficiency and reliability. We did some mock drills as well for the same.
Migration Strategy and Flow
Different migration strategies exist to migrate data from the Cassandra cluster to the ScyllaDB cluster. There are strategy documents and flows created by the ScyllaDB team as well. Still, here we would like to talk about the method that helped us to move Petabytes of data from Cassandra to ScyllaDB without any application downtime. It has been a very straightforward migration for us (It was when we decided on the approach).
We’ll start listing the steps that we executed for the migration of the database:
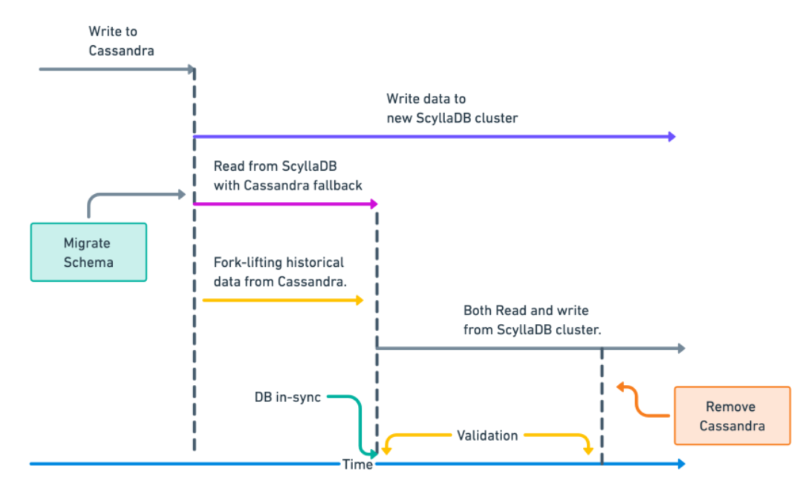
- Creating the same table schema from Apache Cassandra to ScyllaDB (It’s important to understand that migration will occur by the table. Instead of a complete database, list out applications and table mapping. Then migrate each application concerning its table).
cqlsh <cassandra_ip> "-e DESC SCHEMA" > cass_schema.cql cqlsh <scylladb_ip> --file 'adjusted_cass_schema.cql'
Note: We may need to modify the schema a little bit with the properties according to the ScyllaDB. Read more
2. Configure the application to write on the new ScyllaDB cluster; all new writes should go to the ScyllaDB cluster. For reading, a fallback logic should be written. First, it should read from ScyllaDB. If data is available, it should give a response; otherwise, check the data from Cassandra and send a response from that. (Ensure this exercise is taken care of while the traffic amount is manageable; otherwise, it can introduce latency due to fallback logic).

Pseudo code for writing in ScyllaDB:-
cluster := gocql.NewCluster("<scylla_db_ip>")
cluster.Keyspace = "<keyspace_name>"
session, err := cluster.CreateSession()
if err != nil {
panic(err)
}
defer session.Close()
query := session.Query(`INSERT INTO your_table (column1, column2) VALUES (?, ?)`, value1, value2)
The piece of code in Golang for writing the fallback logic:
scyllaSession, err := connectToScyllaDB()
if err != nil {
log.Fatal(err)
}
defer scyllaSession.Close()
dataFromScylla, err := readFromScyllaDB(scyllaSession)
dataFromScylla, err := readFromScyllaDB(scyllaSession)
if err != nil {
log.Println("Error reading from ScyllaDB:", err)
// If not found in ScyllaDB, try reading from Cassandra
cassandraSession, err := connectToCassandra()
if err != nil {
log.Fatal(err)
}
defer cassandraSession.Close()
dataFromCassandra, err := readFromCassandra(cassandraSession)
if err != nil {
log.Fatal("Error reading from Cassandra:", err)
} else {
fmt.Println("Data read from Cassandra:", dataFromCassandra)
}
} else {
fmt.Println("Data read from ScyllaDB:", dataFromScylla)
}
3. Once the application is deployed with fallback logic, it is working fine. The next step would be migrating the historical data from Cassandra to ScyllaDB to remove Cassandra from the picture. We can use dsbulk command to migrate data from Cassandra to ScyllaDB.
# For backup -> dsbulk unload -h <cass_ip> -k keyspace_name -t table_name -url table_name -cl LOCAL_QUORUM --timestamp --ttl # For restore -> dsbulk load -h <scylla_ip> -k keyspace_name -t table_name -url table_name -cl LOCAL_QUORUM --timestamp --ttl

4. As part of the last process after the data migration, we can make Apache end of lifecycle, and we will update the code to read and write both from Cassandra only.
The timeline flow chart will look like this:-
Conclusion
The decision about your data store needs to be made cautiously, especially if you are running your business 24/7 and cannot afford downtime. And there will always be a case that because of scalability, we might need to make decisions like this (migration of complete data store). But before starting, always develop a more hassle-free and convenient strategy for your environment, just like we did in our case!
Thanks for reading. I’d appreciate your feedback. Please leave a comment below if you have any suggestions or questions.
Cheers till next time!!
Blog Pundits: Sandeep Rawat
OpsTree is an End-to-End DevOps Solution Provider.
Connect with Us


