
For organizations to make effective decisions and remain competitive, data is essential.
An enterprise stores 10 PetaBytes (PB) of data on average. In addition to being expensive to handle, such an amount of data is also challenging to evaluate to extract useful insights.
So traditional data management methods need to be closely linked with modern technologies to keep up with the increasing volumes of data.
Serverless computing relieves you of the burden of operating servers so that you can concentrate on what matters—getting value from data.
Let us explore more about the benefits of going serverless for engineering data in this blog post.
Building Scalable Data Workflows: How Going Serverless Complements Data Engineering
With serverless architecture, resource allocation is dynamically managed by the cloud provider, which automatically scales up or down in response to demand.
In essence, serverless architecture frees your data engineering team from managing servers so they can concentrate entirely on collecting data from insights.
The following are some advantages of using a serverless architecture for intricate data analysis:
- Scalability: The inherent scalability of serverless architecture is one of its most important benefits for data processing.
Data processing jobs can scale autonomously with serverless technology according to demand. Serverless technology can dynamically assign resources to ensure optimal performance without the need for manual intervention, regardless of the volume of data being processed, from small batches to large influxes of information.
- Cost-effectiveness: Serverless architecture is based on a pay-per-use payment model; you only pay for the resources that your data operations use. Because of this, it is extremely economical, particularly for workloads with varying processing requirements.
Compared to typical hosting arrangements, you may drastically save operational costs because you aren’t paying for unused resources.
- Decreased Operational Overhead: Overseeing data process infrastructure can be difficult and time-consuming. This operational overhead is removed by the serverless architecture, which abstracts away server management responsibilities.
You can forget about worrying about setting up networking, provisioning servers, or updating software when you use serverless. By handling these duties on your behalf, the cloud provider frees up your staff to concentrate on data processing and analysis.
- Faster Time-to-Insight: Data engineers can quickly iterate and release updates to data workflows with minimal downtime thanks to a serverless architecture.
Serverless functions enable you to create real-time data pipelines that provide stakeholders with insights more quickly since they are event-driven and may be triggered by a variety of data sources. This becomes crucial in professional settings like banking, healthcare, and other industries where prompt insights can have a significant impact.
- Easier Integration with Third-Party Services: Data engineers can quickly iterate and release updates to data workflows with minimal downtime thanks to a serverless architecture.
Serverless functions enable you to create real-time data pipelines that provide stakeholders with insights more quickly since they are event-driven and may be triggered by a variety of data sources. This becomes crucial in professional settings like banking, healthcare, and other industries where prompt insights can have a significant impact.
Why Choose Serverless Data Architecture for Data Pipelines
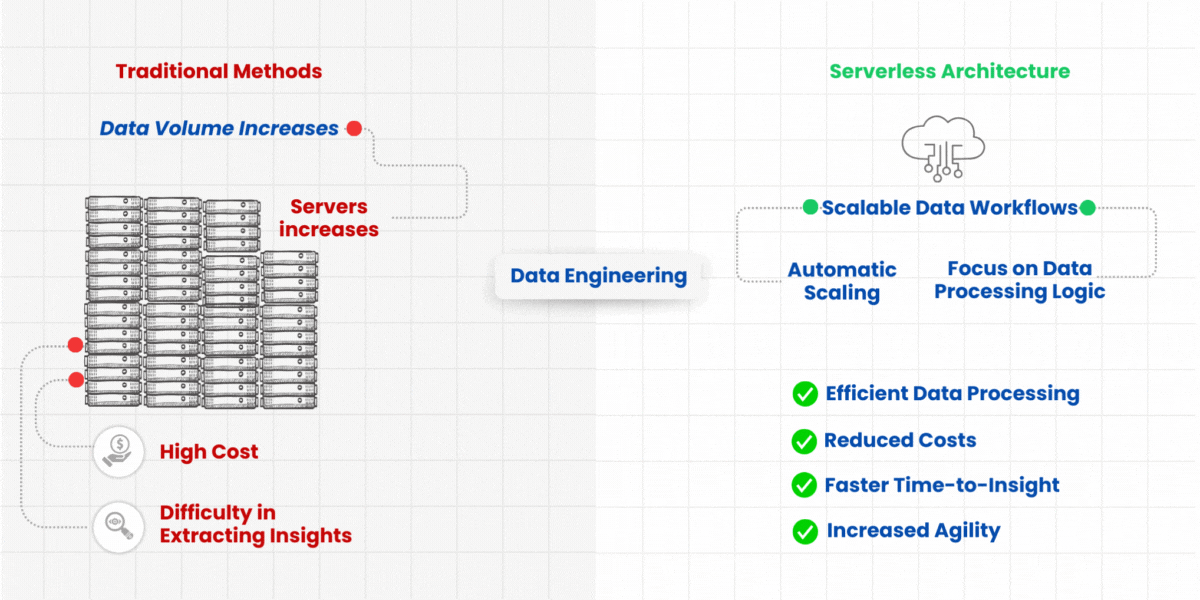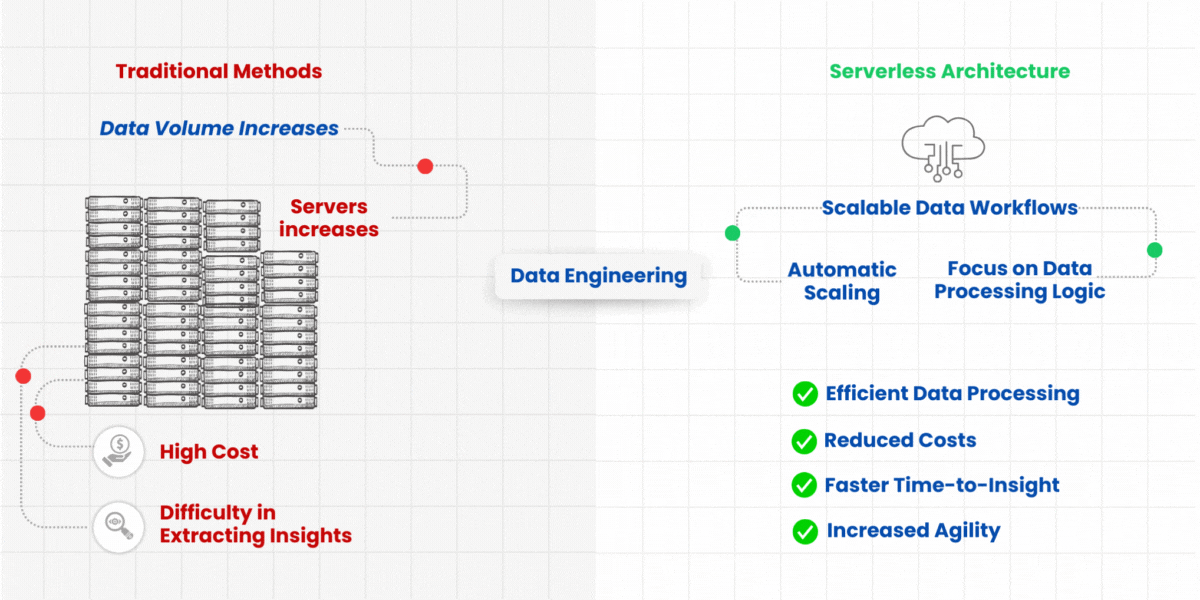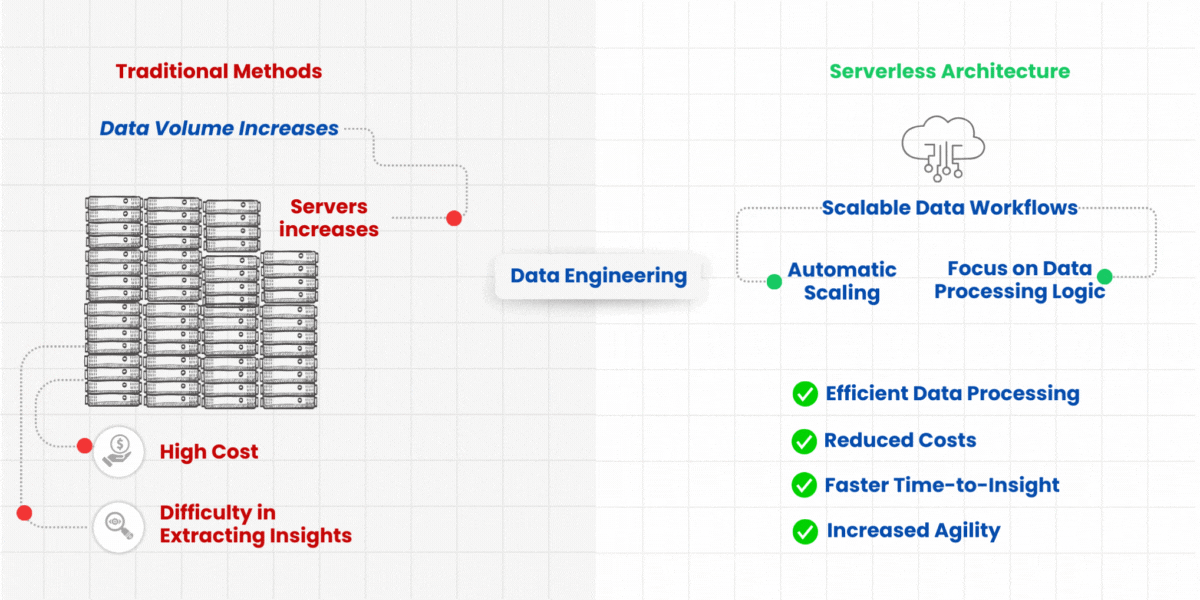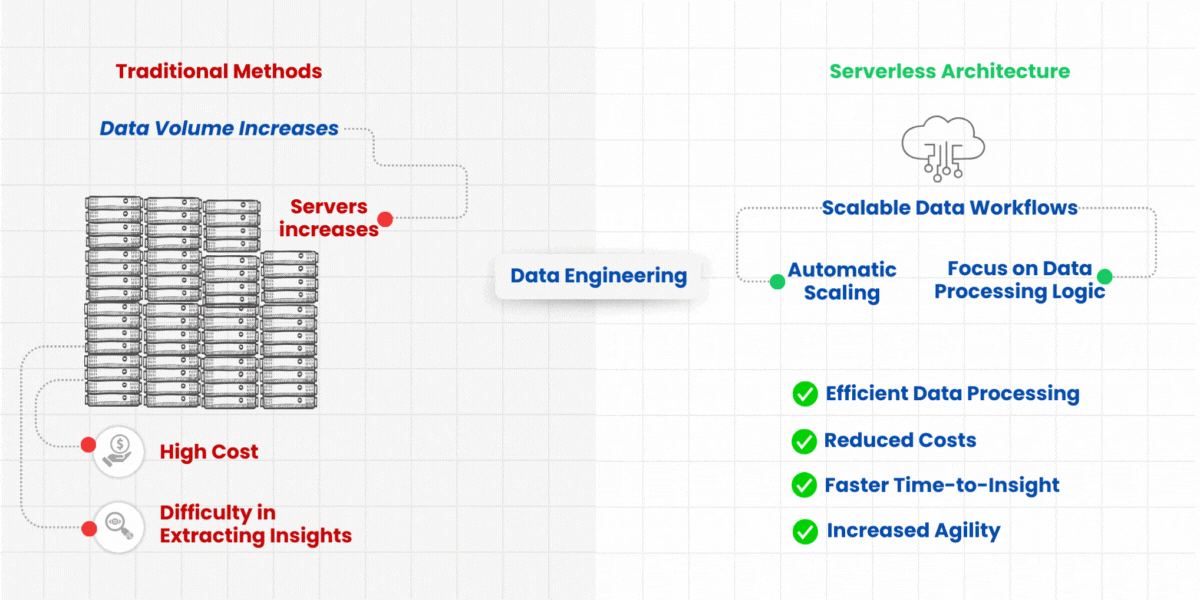 Data pipelines are important to transform data and analyze it into insights. While traditional data pipelines require you to configure infrastructure, dependencies, and code, serverless pipelines let you focus solely on the data processing logic itself.
Data pipelines are important to transform data and analyze it into insights. While traditional data pipelines require you to configure infrastructure, dependencies, and code, serverless pipelines let you focus solely on the data processing logic itself.
Here’s more on how serverless data pipelines help you overcome obstacles and produce more data:
- Strengthening Data Pipelines with Event-Driven Triggers: Serverless data pipelines offer flexibility and scalability by processing and managing data without a server setup. They utilize cloud services like AWS Lambda, Google Cloud Functions, or Azure Functions to execute code in response to events.Additionally, event-driven triggers automate processing based on events such as file uploads, database changes, or API calls. Thus, enabling immediate reactions for real-time processing. They also facilitate easy integration with other cloud services and external systems, ensuring adaptability to changing needs.
- Faster Development and Deployment Cycles: Serverless functions can be developed and deployed independently, allowing teams to iterate quickly and release updates to data pipelines without disrupting other components of the system. This agility is pivotal in dynamic environments where data requirements change frequently or new data sources need to be integrated rapidly.
- Improved Resource Utilization: Serverless technologies dynamically handle resource allocation. Thus freeing engineers from the task of manually provisioning servers to meet peak demands. This not only reduces the complexity of infrastructure management but also ensures optimal resource utilization, allowing organizations to achieve greater efficiency and cost-effectiveness in their data processing operations.
Approaching Data Engineering With Cloud / Serverless Architecture?
A more effective method of managing and processing data is to approach data engineering through cloud or serverless architecture. Using cloud services, enterprises may offload the burden of infrastructure administration and expand resources to meet changing demands.
Specifically, the serverless architecture allows code to be executed in response to events, facilitating real-time processing and increased flexibility.
While switching to a serverless architecture for data management can have a lot of advantages, the real difficulty is making sure your servers are set up to work with your current workflow. Therefore, it’s critical to choose a partner who can assist you in easily configuring your servers to match your current workflows.
If you have any questions about data engineering using serverless architecture, feel free to reach out to us at connect@opstree.us. Whether you’re curious about data engineering practices or considering a switch to serverless architecture for better data management, we’re here to assist you.