
Apache Hudi (Hadoop Upserts Deletes and Incrementals) is an advanced data management framework designed to efficiently handle large-scale datasets. One of its standout features is time travel, which allows users to query historical versions of their data. This feature is essential for scenarios where you need to audit changes, recover from data issues, or simply analyze how data has evolved over time. In this blog post, we’ll walk through the process of setting up Hudi for time travel queries, using AWS Glue and PySpark for a hands-on example.
1. Getting Started: Importing Libraries and Creating Spark Context
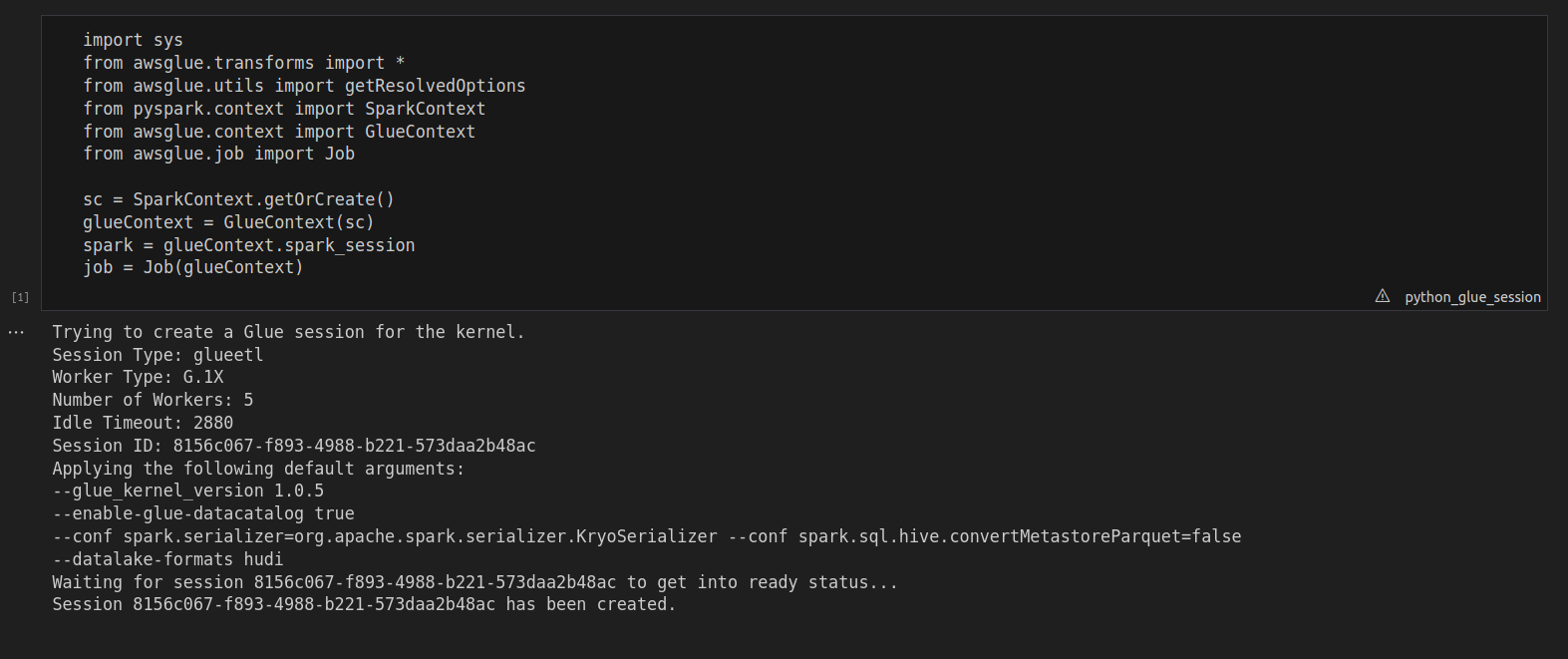
First, ensure you have all the necessary libraries in place. In this example, we’ll be using PySpark along with Hudi on AWS Glue notebook to manage data and run our queries. Make sure to import the relevant libraries and establish a Spark and Glue context before proceeding 
2. Setting Up Your Hudi Table
Before we can explore time travel queries, you need to set up a Hudi table where your data will reside. To do this, define your database and table names, and provide an S3 path where your data will be stored. 
3. Creating and Populating the Hudi Table
After defining the table, you can now generate data and create a DataFrame in PySpark. Once your data is ready, write it to Hudi. This action creates the initial version of your dataset. 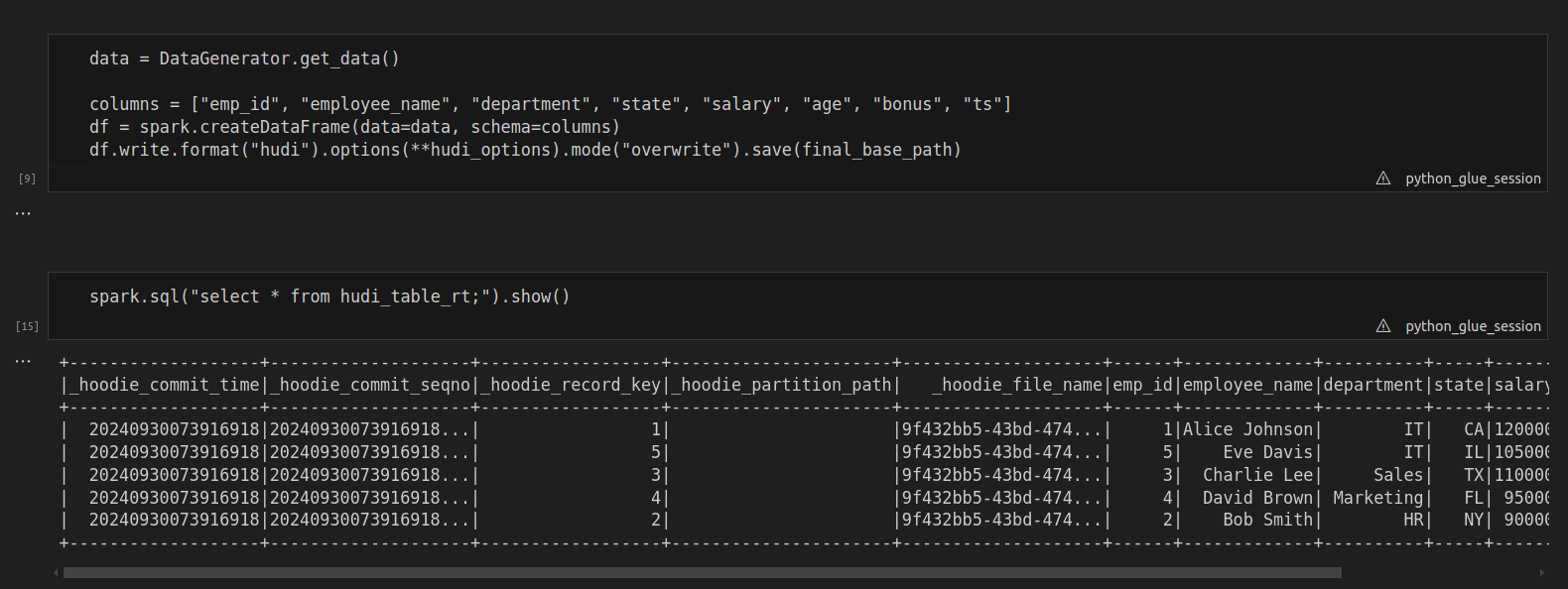
4. Working with Time Travel Queries
To demonstrate the power of time travel in Hudi, we’ll make updates to the data and observe how these changes are reflected at different points in time. For example, you can append new records to the table, which will trigger Hudi to create a new version of the data while retaining the previous versions in parquet files. We also updated the current record. After appending, you will notice that a new parquet file is created, while the previous records remain intact. Next, we will update an existing record: 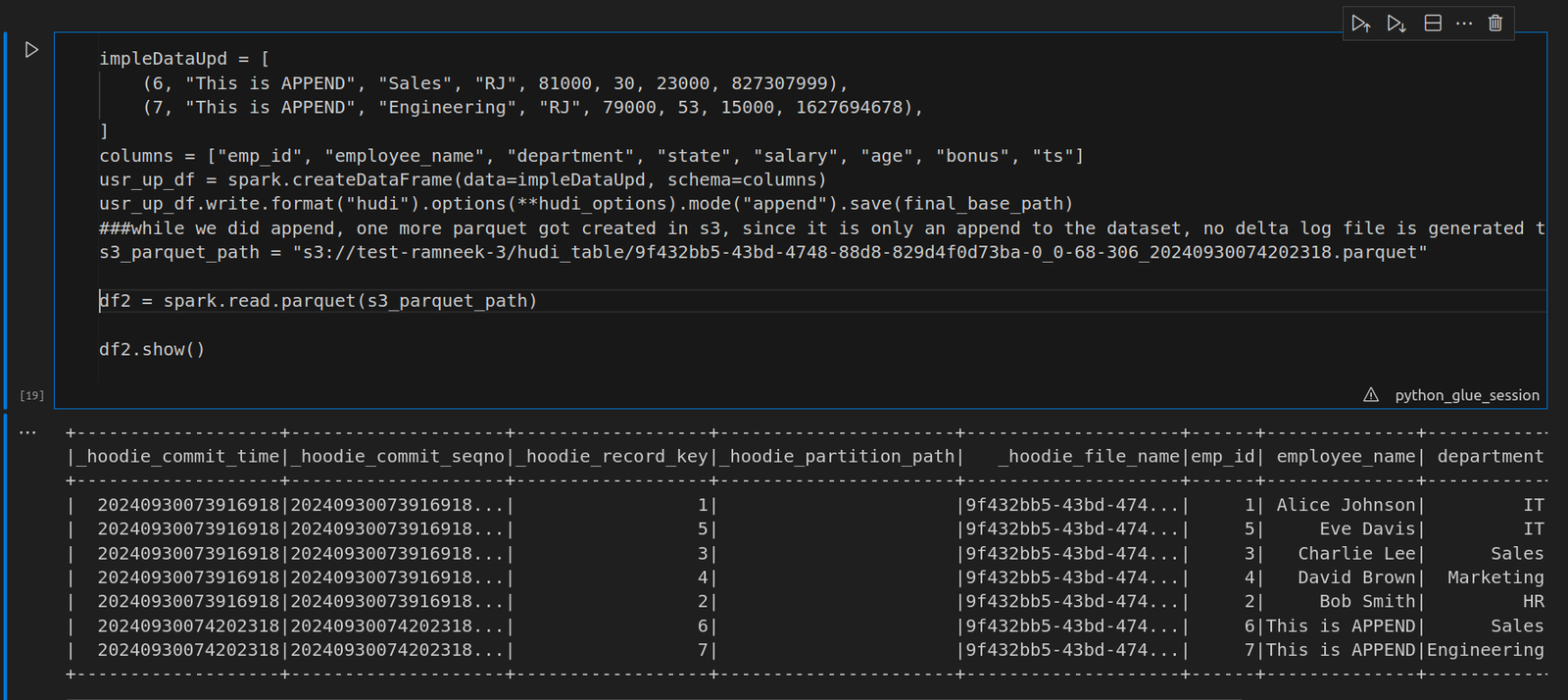
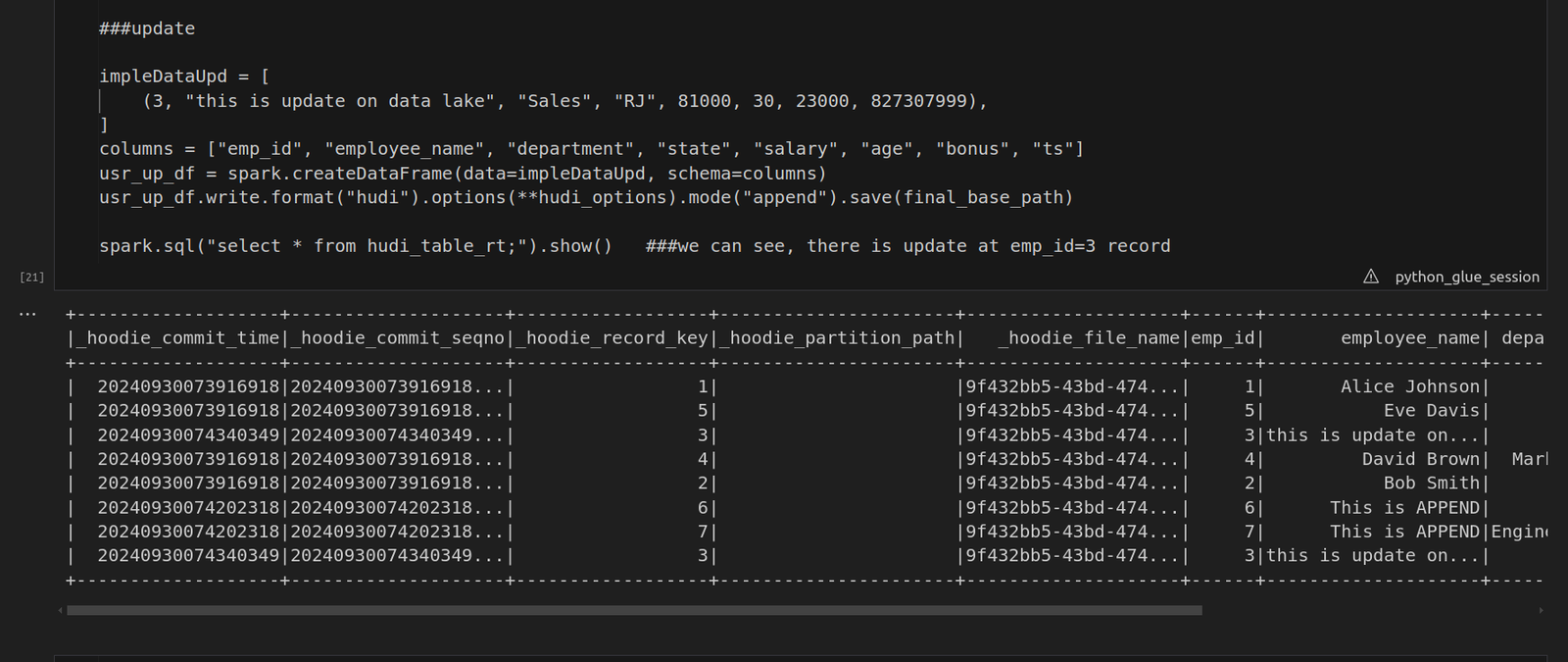
5. Listing Commit Times for Time Travel and performing a Time Travel Query:
In Hudi, commit times (also called instant times) play a key role in versioning. Each time data is written or updated, Hudi stores a new commit time. To perform a time travel query, you first need to list these commit times and select the one you’d like to query. · meta_df = spark.read.format(“hudi”).load(final_base_path) This line reads the Hudi table from the S3 path (final_base_path) into a Spark DataFrame. Hudi maintains metadata along with the data itself, including commit times (known as instant times) stored in the _hoodie_commit_time field. The Hudi table can store multiple versions of the data through these commit times. · meta_df.createOrReplaceTempView(“hudi_metadata”) Here, a temporary SQL view called “hudi_metadata” is created from the DataFrame meta_df. This allows us to run SQL queries directly on the metadata of the Hudi table. · commit_time_df = spark.sql(“SELECT distinct(_hoodie_commit_time) as commit_time FROM hudi_metadata order by commit_time desc”) This SQL query fetches all distinct commit times (_hoodie_commit_time) from the Hudi table’s metadata. 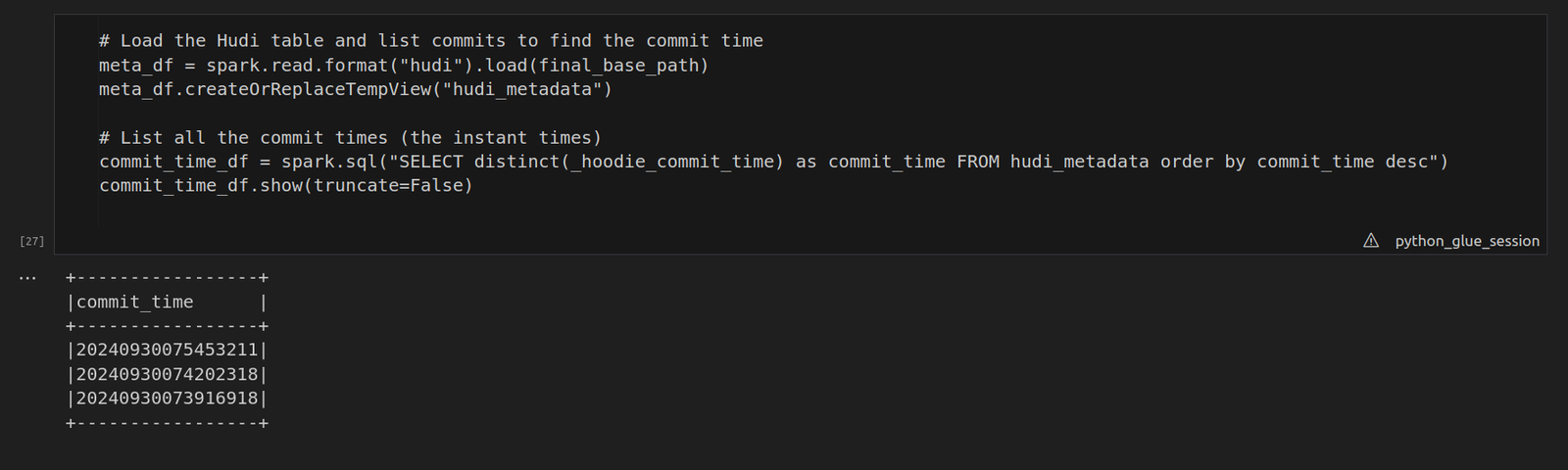 To perform a time travel query, use the commit time you retrieved earlier. By specifying the commit time using the as.of.instant option, Hudi allows you to view the state of the data as it existed at that specific point in time.
To perform a time travel query, use the commit time you retrieved earlier. By specifying the commit time using the as.of.instant option, Hudi allows you to view the state of the data as it existed at that specific point in time. 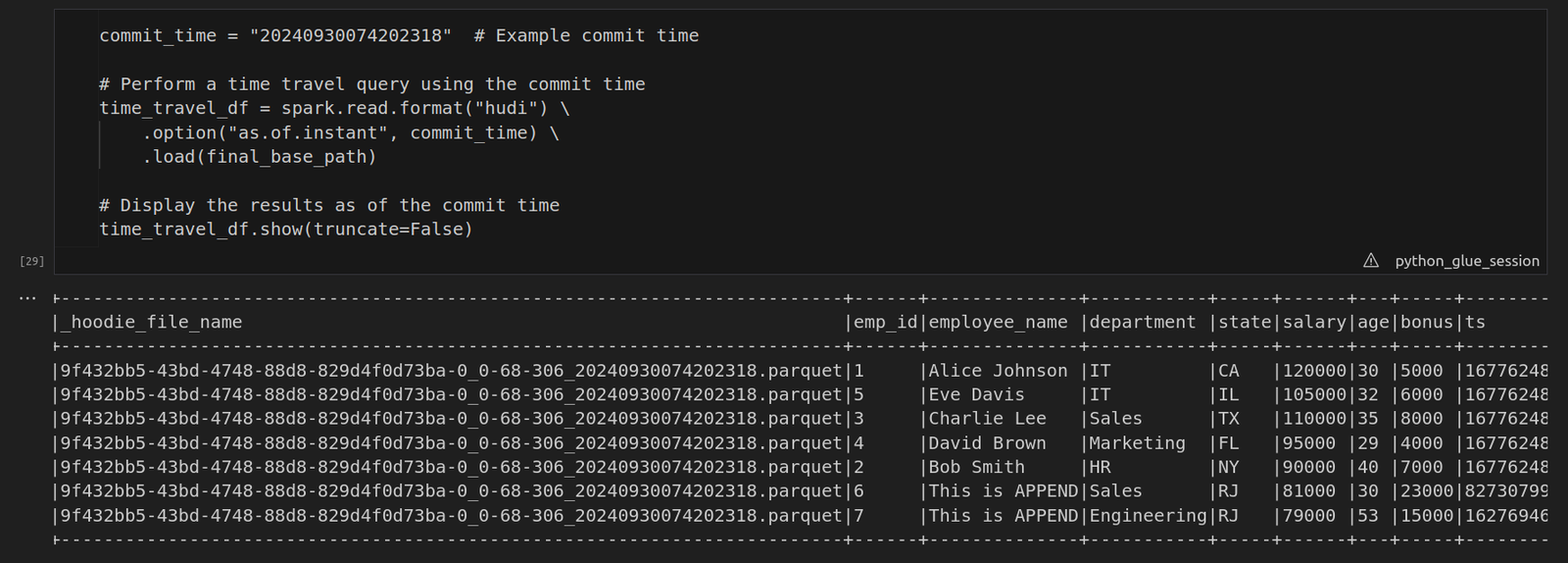
6. Why Time Travel is Important
Apache Hudi’s time travel capability is a game-changer for data management. It provides:
- · Data Auditing: You can review the state of the data at any past commit.
- · Data Rollback: If an issue arises in a recent commit, you can easily revert to a previous version of the data.
- . Historical Analysis: Analyze how your data has evolved without storing multiple copies manually.
Conclusion
Time travel in Apache Hudi is a powerful feature for querying historical data versions. It enables efficient data auditing, rollback, and analysis, which are crucial for any modern data pipeline. By following the steps in this blog, you can quickly set up Hudi and leverage this feature in your workflows. Whether you’re working in AWS Glue or a similar environment, Hudi’s time travel queries simplify managing complex datasets.
Connect With Us
Connect With Us