
In the world of machine learning, managing data, code, and models efficiently is crucial for ensuring reproducibility and collaboration. If you’re working on machine learning or data science projects, you’ve likely struggled with managing large datasets, models, and experiment results.
While Git is great for tracking code, it wasn’t built to handle large files or complex workflows. This is where DVC (Data Version Control) shines – helping you track datasets, models, and experiments alongside your code, making your projects scalable and reproducible.
What is DVC?
DVC (Data Version Control) is an open-source tool designed for data science and machine learning workflows. It extends Git’s version control capabilities to handle large datasets and model files. Think of it as a specialized Git for data and experiments, allowing teams to:
· Track and version datasets and models
· Share files through remote storage
· Reproduce experiments with consistency
Just like Git tracks code changes, DVC tracks changes to your data and models.
🧠 Why Data Versioning Matters?
Data versioning is essential because:
· It enables reproducibility, so results can be validated
· Promotes collaboration across teams and environments
· Helps with auditing and traceability — track data history
· Prevents costly mistakes due to using the wrong dataset/model version
· Simplifies debugging and troubleshooting
🛠️ Prerequisites
Before you start with DVC, ensure you have:
· Basic knowledge of Git and the command line
· Python (preferably 3.9)
· Conda (for creating a virtual environment)
· A Git-initialized project folder
Getting Started With DVC
Let’s walk through setting up DVC in a machine learning project.
1. Install DVC
Start by creating a clean environment and installing DVC:
$ conda create -n dvc_demo python=3.9 -y
$ conda activate dvc_demo
$ pip install dvc
2. Initialize DVC in Your Project
Navigate to your project directory and initialize DVC:
$ dvc init
This sets up the necessary DVC config files and hooks it into Git.
3. Configure Remote Storage
Your actual data won’t be stored in Git — DVC uses remote storage for that. You can use cloud (S3, GCS, Azure) or local storage:
$ dvc remote add -d myremote <remote_storage_url>
Examples:
$ dvc remote add -d myremote s3://my-bucket/my-folder
$ dvc remote add -d myremote /path/to/local/storage
· -d sets this remote as default
· Myremote is your alias for the remote
4. Track Data or Model Files
Let’s say you’ve trained a model and saved the checkpoint:
$ dvc add models/best-checkpoint.ckpt
This creates a .dvc file that references the model without storing the actual data in Git.
5. Commit Changes to Git
Now, commit the DVC metadata file and updates to .gitignore:
$ git add models/best-checkpoint.ckpt.dvc models/.gitignore
$ git commit -m “Track model checkpoint using DVC”
6. Push Data to Remote
Push the data file to the remote storage:
$ dvc push
7. Retrieve Files When Needed
To download data from remote storage (on a different machine or after cleanup):
$ dvc pull
8. Reproduce Pipelines
If you set up a pipeline with dvc.yaml, you can rerun the workflow and reproduce the results:
$ dvc repro
📂 Understanding DVC Through Project Files
Let’s break down how DVC organizes your project internally.

.dvc file tracks the best-checkpoint.ckpt without storing it in Git
Sample .dvc Metafile (trained_model.dvc)
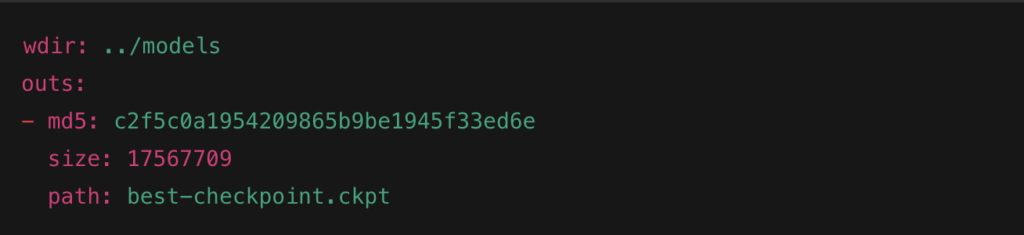
.dvc file tracks the model file best-checkpoint.ckpt without storing it in Git. It saves the file’s location, size, and a unique hash to manage versions easily.
Benefits of Using DVC
· Lightweight Git Repo: Keep large data and models out of Git
· Team Collaboration: Seamless data sharing via cloud/local storage
· Experiment Management: Track what data, code, and parameters led to each result
· CI/CD Friendly: Integrate DVC into ML pipelines for MLOps
Conclusion
DVC is a powerful tool for managing machine learning projects, providing version control for large files and ensuring reproducibility across different experiments. By integrating DVC into your workflow, you can handle datasets and models as efficiently as you handle your code with Git, enhancing collaboration and maintainability in machine learning projects.