
“Your code doesn’t just ship — it survives a gauntlet of digital Darwinism where only the fittest features reach users.”
How One PostgreSQL Version Mismatch Cost a Fortune 500 Company $4.7 Million
TL; DR — When Simple Becomes Catastrophic
Last month, two digits in a database version number brought at a Fortune 500 company a production outage that cost $4.7 million in lost revenue. The root cause? Their staging environment was running on PostgreSQL 13 while production was on PostgreSQL 15. A simple version mismatch became a career-ending incident.
This isn’t just another “environments matter” story. This is about the invisible architecture of trust that separates unicorn startups from digital graveyards.
The Psychology of Environment Neglect
Before we dive into the technical blueprint, let’s address the elephant in the room: why do smart engineers build terrible environment strategies?
The Cognitive Traps
- The Optimism Bias: “This simple change won’t break anything”
- The Complexity Aversion: “Setting up proper staging is too much work”
- The Success Illusion: “We’ve deployed 50 times without issues”
Research from MIT’s Computer Science Lab shows that teams with poor environment discipline have 3.2x higher burnout rates and 40% more weekend emergency calls. Your environment strategy isn’t just technical debt — it’s human debt.
The Seven Circles of Software Hell
Think of environments not as linear stages, but as concentric circles of trust — each one a fortress wall protecting your users from chaos.

The Environment Maturity Matrix™
Here’s the brutal truth about where your team really stands:
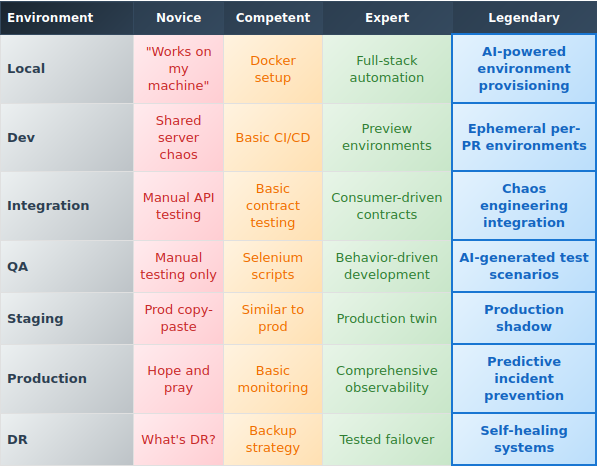
Where does your team sit? Be honest. Your users’ trust depends on it.
The Bookstore That Almost Wasn’t
Let me tell you about Sarah, a senior engineer at a promising e-commerce startup. Her team was racing to launch their MVP bookstore before the holiday season.
Week 1: The Confidence High
- Local: Sarah builds a beautiful login system with JWT tokens
- Dev: Team integrates the shopping cart — everything works perfectly
- Confidence Level: 95%
Week 2: The First Cracks
- Integration: Payment gateway returns mysterious 500 errors in dev
- Root Cause: Dev environment using sandbox Stripe keys, but wrong API version
- Confidence Level: 80%
Week 3: The QA Revelation
- QA Testing: Load testing reveals cart abandonment under 100 concurrent users
- Root Cause: Database connection pooling not configured
- Confidence Level: 60%
Week 4: The Staging Shock
- Staging Demo: CEO’s demo fails — checkout button doesn’t work
- Root Cause: Staging using different CDN configuration than production
- Confidence Level: 30%
Launch Day: The Production Paradox
- Go-Live: Site launches, immediate success… then crashes after 2 hours
- Root Cause: Production Redis cluster not configured for high availability
- Result: $180K in lost sales, 6-month recovery
The Twist: All of this was preventable with proper environment discipline. Sarah’s team implemented the strategies below and became the fastest-growing e-commerce platform in their sector.
The Trust Architecture Blueprint
1. The Environment DNA Test
Before building anything, audit your current setup:
# The Environment Health Check
echo "Environment Parity Score:"
diff <(docker inspect prod_db) <(docker inspect staging_db) | wc -l
echo "Config Drift Points: $?"
# The Confidence Metric
git log --oneline --since="1 month ago" | grep -i "hotfix\|emergency" | wc -l
echo "Panic Deployments This Month: $?"
2. The Three Laws of Environment Robotics
Law 1: An environment may not harm user experience through action or inaction
Law 2: An environment must obey deployment commands except where such commands conflict with Law 1
Law 3: An environment must protect its own existence except where such protection conflicts with Laws 1 and 2
The Observable Trust Network
Metrics That Actually Matter
Stop drowning in vanity metrics. Focus on these Trust Indicators:

The Trust Dashboard
Create a single dashboard that answers one question: “Can we deploy right now?”
# trust-dashboard.yml
environments:
dev:
health_check: "https://dev.api.com/health"
expected_response: 200
trust_score: 85
staging:
health_check: "https://staging.api.com/health"
expected_response: 200
trust_score: 92
production:
health_check: "https://api.com/health"
expected_response: 200
trust_score: 99
deployment_readiness:
all_environments_healthy: true
no_active_incidents: true
business_hours: true
approval_granted: true
can_deploy: true # This is your North Star
The Implementation Playbook
Phase 1: Stop the Bleeding (Week 1)
# Emergency Environment Audit
./audit-environments.sh
# Expected output: List of critical mismatches
# Quick Wins
- Add health checks to every environment
- Implement basic blue-green deployment
- Set up environment parity monitoring
Phase 2: Build the Foundation (Weeks 2–4)
# Infrastructure as Code
terraform init
terraform plan -var-file="environments/staging.tfvars"
terraform apply
# GitOps Pipeline
kubectl apply -f gitops/
argocd app sync bookstore-staging
Phase 3: Achieve Environment Nirvana (Weeks 5–8)
# Chaos Engineering
chaos-monkey --target=staging --duration=30m
# Measure: How quickly does your system recover?
# Predictive Monitoring
./deploy-ml-anomaly-detection.sh
# Result: Catch issues before they become incidents
The Secret Weapon: Environment Personalities
Here’s an advanced technique most teams miss — give each environment a distinct personality that matches its purpose:
- Local: The Creative Genius (fast, experimental, forgiving)
- Dev: The Team Player (collaborative, integrated, social)
- Integration: The Perfectionist (strict contracts, zero tolerance for API drift)
- QA: The Skeptic (questions everything, finds edge cases)
- Staging: The Executive (polished, business-ready, impressive)
- Production: The Guardian (stable, monitored, protective)
- DR: The Phoenix (resilient, tested, ready to rise)
When your team thinks of environments as personalities rather than just servers, they naturally treat them with the appropriate care and feeding.
The $4.7 Million Lesson Learned
Remember that Fortune 500 company from the beginning? Here’s what they implemented after their expensive lesson:
- Environment DNA Matching: Automated verification that all environments share identical configurations
- Trust Score Monitoring: Real-time dashboard showing deployment readiness
- Progressive Delivery: Canary deployments with automatic rollback triggers
- Chaos Engineering: Regular failure injection to test environment resilience
Result: Zero production incidents in 8 months, 40% faster feature delivery, and a $12M increase in annual revenue.
Let’s Check all Types that exists
| Environment | Purpose | Who Uses It | What Happens Here | Feels Like |
|---|---|---|---|---|
| Local | For developers to write and test code | Developers | You write, run, and debug code on your own machine | Your laptop playground |
| Sandbox | Isolated testing or experimentation | Developers/Testers | Safe place to try new features or integrations without affecting anyone else | A private lab |
| Development (Dev) | Integrate code and test with team | Developers | Code from multiple devs is combined and tested | Shared playground |
| Integration | Test interactions between components | Developers / QA | Microservices or modules are tested together | Mini city simulation |
| Testing / QA | Formal testing happens here | QA Engineers / Testers | Bugs are found, performance is checked | Controlled testing lab |
| Staging / Pre-Prod | Replica of production, used before release | Dev, QA, Product Owners | Final testing happens here; realistic user data often used | Dress rehearsal |
| UAT (User Acceptance Testing) | Used by clients or business for final approval | Clients / Stakeholders | End-users verify that the product meets their expectations | Trial by the real users |
| Production (Prod) | Live system used by real users | Everyone (users) | Real traffic, real users, real stakes | The real world |
| Disaster Recovery (DR) | Backup of production | DevOps / Infra team | Activated if production fails | Emergency backup location |
| Performance / Load Testing | Used for stress/load tests | QA / DevOps | Simulates real-world traffic to measure app limits | Gym for your app |
| Canary | Small % of real users test a new feature | DevOps / Product | Rollout of a new version to a limited audience | Soft launch |
| Blue-Green | Two identical prod environments (Blue & Green) | DevOps | Switch between Blue & Green for zero-downtime releases | Dual runways for planes |
Your Environment Manifesto
Print this out and put it on your wall:
WE BELIEVE
That every environment is sacred
That trust is earned through consistency
That automation beats heroics
That monitoring precedes understanding
That failure is a teacher, not an enemy
That production is the only truth
WE COMMIT
To treat environments as products
To measure what matters
To automate what we can
To monitor what we must
To learn from every failure
To ship with confidence, not hope
Conclusion: The Environment Endgame
Your environment strategy isn’t just about deployment — it’s about engineering empathy. Every environment is a promise to your future self, your teammates, and your users.
The companies that win in 2025 won’t have the best features — they’ll have the most trustworthy deployment pipelines. They’ll sleep soundly while their competitors get paged at 3 AM.
The question isn’t whether you can afford to invest in proper environment discipline. The question is whether you can afford not to.
“In the end, we will remember not the words of our enemies, but the silence of our environments when we needed them most.”
Take Action Now
- Audit: Run the Environment Health Check on your current setup
- Measure: Implement the Trust Indicators dashboard
- Improve: Pick one environment and make it legendary
- Scale: Apply learnings across your entire pipeline
- Share: Teach your team the Environment Manifesto
The path to deployment nirvana starts with a single commit. Make it count.
Further Reading
- “The Phoenix Project” by Gene Kim (The DevOps novel that started it all)
- Google SRE Workbook Chapter 14: “Testing for Reliability”
- “Accelerate” by Nicole Forsgren (The science behind high-performing teams)
- Research Paper: “Environment Drift and Its Impact on Software Reliability” — ACM Digital Library
- Case Studies: Netflix Chaos Engineering Blog — How they test in production