
Redis as a Database
Sometimes getting data from disks can be time-consuming. In order to increase the performance, we can put the requests those either need to be served first or rapidly in Redis memory and then the Redis service there will keep rest of the data in the main database. So the whole architecture will look like this:-
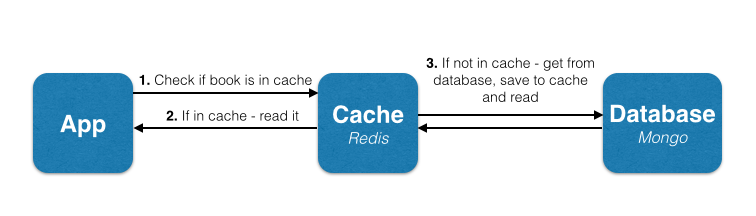
Redis Master-Slave Replication
Beginning with the explanation about Redis Master-Slave. In this phenomenon, Redis can replicate data to any number of nodes. ie. it lets the slave have the exact copy of their master. This helps in performance optimizations.
I bet now you can use Redis as a Database.
Redis Cluster
A Redis cluster is simply a data sharding strategy. It automatically partitions data across multiple Redis nodes. It is an advanced feature of Redis which achieves distributed storage and prevents a single point of failure.
Replication vs Sharding
Replication is also known as mirroring of data. In replication, all the data get copied from the master node to the slave node.
Sharding is also known as partitioning. It splits up the data by the key to multiple nodes.
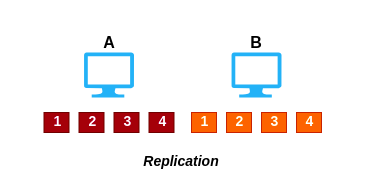
As shown in the above figure, all keys 1, 2, 3, 4 are getting stored on both machine A and B.
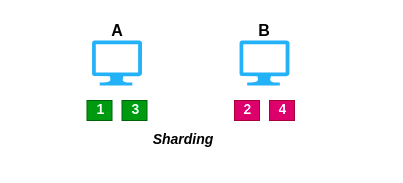
In sharding, the keys are getting distributed across both machine A and B. That is, the machine A will hold the 1, 3 key and machine B will hold 2, 4 key.
Migration
Unfortunately, redis doesn’t have a direct way of migrating data from Redis-Master Slave to Redis Cluster. Let me explain it to you why?
We can start Redis service in either cluster mode or standalone mode. Now your solution would be that we can change the Redis Configuration value on-fly(means without restarting the Redis Service) with redis-cli. Yes, you are absolutely correct we can change the Redis configuration on-fly but unfortunately, Redis Mode(cluster or standalone) can’t be decided on-fly, for that we have to restart the service.
I guess now you guys will understand my situation :).
For migration, there are multiple ways of doing it. However, we needed to migrate the data without downtime or any interruptions to the service.
We decided the best course of action was a steps process:-
- Firstly we needed to create a different Redis Cluster environment. The architecture of the cluster environment was something like
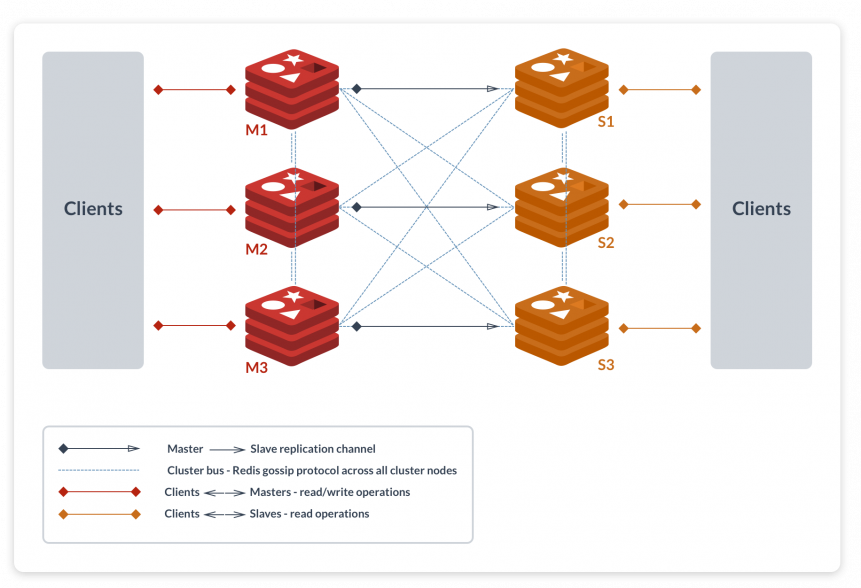
- The next step was to update all the services (application) to send all the write operations to both servers(cluster and master-slave). The read commands (GET) will still go to the old setup.
- But still, we don’t have the guarantee that all non-expirable data would make it over. So we can run a step to iterate through all of the keys and DUMP/RESTORE them into the new setup.
- Once the new Redis Server looks good we could make the appropriate changes to the application to point solely to the new Redis Server.
I know the all steps are easy except the second step. Fortunately, redis provides a method of key scanning through which we can scan all the key and take a dump of it and then restore it in the new Redis Server.
To achieve this I have created a python utility in which you have to define the connection details of your old Redis Server and new Redis Server.
You can find the utility here.
https://github.com/opstree/redis-migration
I have provided the detail information on using this utility in the README file itself. I guess my experience will help you guys while redis migration.
Replication or Clustering?
I know most people have a query that when should we use replication and when clustering :).
If you have more data than RAM in a single machine, use Redis Cluster to shard the data across multiple databases.
If you have less data than RAM in a machine, set up a master-slave replication with sentinel in front to handle the fai-lover.
The main idea of writing this blog was to spread information about Replication and Sharding mechanism and how to choose the right one and if mistakenly you have chosen the wrong one, how to migrate it from :).
There are multiple factors yet to be explored to enhance the flow of migration if you find that before I do, please let me know to improve this blog.
I hope I explained everything and clear enough to understand.
Thanks for reading. I’d really appreciate any and all feedback, please leave your comment below if you guys have some feedbacks.
Happy Coding!!!!
Initially the script reference from taken here
https://gist.github.com/aniketsupertramp/1ede2071aea3257f9bb6be1d766a88f
