
Well-optimized ETL processes provide high-quality data flowing through your pipelines.
However, studies suggest that more than 80% of enterprise data is unstructured, often leading to inaccuracies in analytics platforms.
This can create a misleading picture for businesses and affect overall decision-making.
To address these challenges, implementing best practices can help data professionals refine their data precisely.
In this blog post, we will explore some proven key ETL optimization strategies for handling massive datasets in large-scale pipelines.
Let us start:
Overview of The ETL Processes (Extract, Transform and Load)
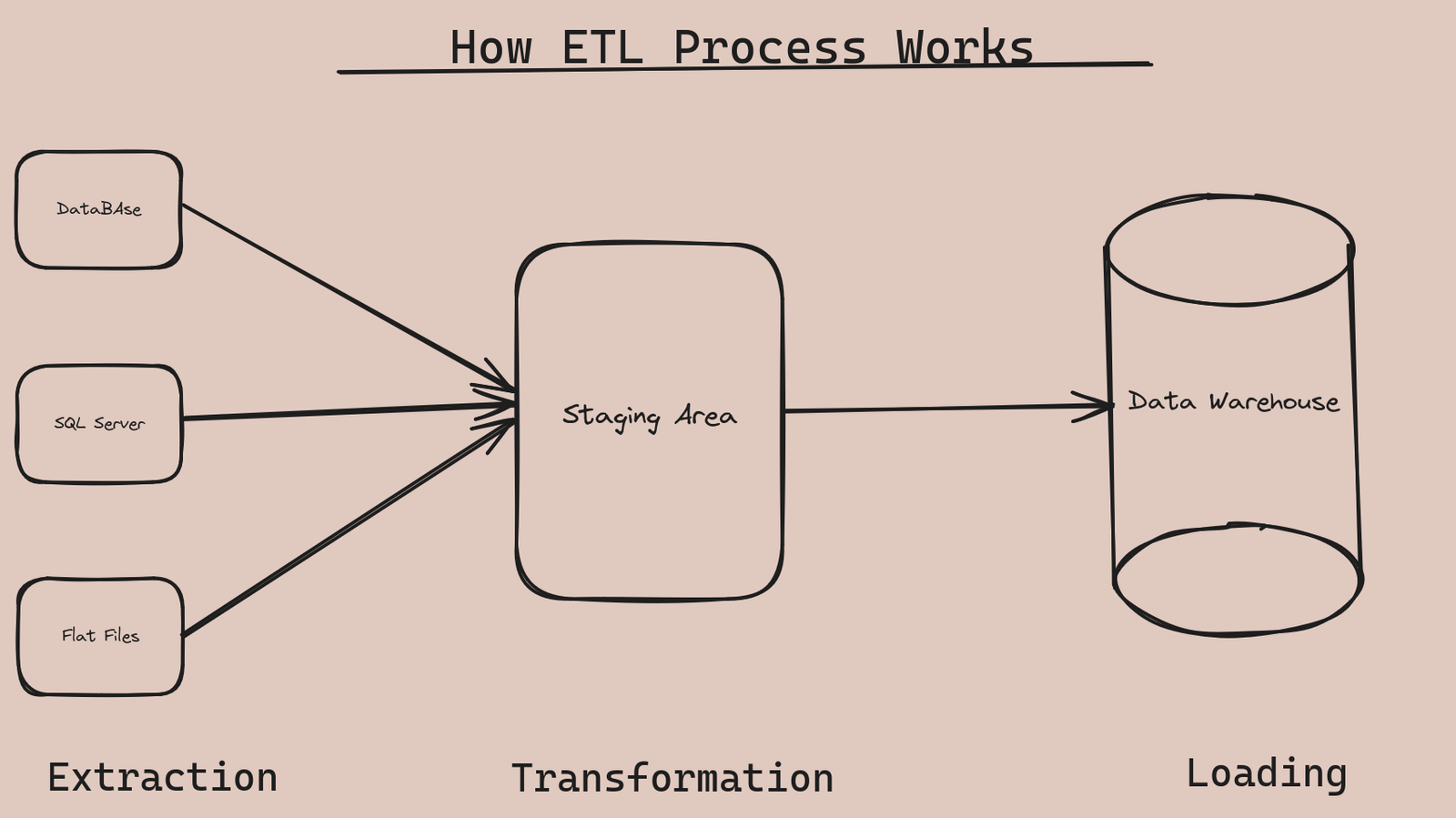
ETL stands for Extract, Transform, and Load. It is defined as a set of processes to extract data from one system, transform it, and load it into a central repository.
This central repository is known as the Data Warehouse.
The choice of ETL (Extract, Transform, Load) architecture can significantly impact efficiency and decision-making.
Two popular ETL approaches—batch processing and real-time processing—offer unique advantages tailored to specific needs and scenarios.
Batch Processing: This traditional method involves collecting data over a period and processing it in large chunks at scheduled intervals. Batch processing is ideal for tasks that do not require immediate data updates, such as end-of-day reporting, data warehousing, and periodic data migrations.
Its main advantage lies in its ability to handle high volumes of data efficiently, often during off-peak hours, reducing the strain on system resources.
Stream (or real-time) Processing: Also known as streaming ETL, real-time processing deals with data as it arrives, providing near-instantaneous updates and insights.
This architecture is essential for applications that demand up-to-the-minute information, such as fraud detection, real-time analytics, and personalized customer experiences.
The key benefit of real-time processing is its ability to respond quickly to changing data, enabling more agile decision-making and immediate action.
Strategies for Optimizing ETL Processes in Large-Scale Data Pipelines
1. Parallel Processing with Data Sharding
Parallel processing with data sharding enhances the efficiency and scalability of ETL workflows by breaking down large datasets into smaller, manageable pieces called shards.
This allows organizations to process data concurrently across multiple nodes, significantly reducing processing time, especially with massive data volumes.
To implement parallel processing effectively, strategic planning is crucial. This involves carefully selecting appropriate sharding keys and ensuring balanced data distribution.
Tools such as Apache Hadoop, Apache Spark, and Google BigQuery provide robust frameworks for parallel processing, making it easier for organizations to adopt and scale this approach.
Real-world applications, like Facebook, use Hive on Hadoop in their data warehouse. This tells us about the scalability and efficiency achieved through parallel processing and data sharding.
2. Data Ingestion with Stream Processing Frameworks
Stream processing frameworks help in optimizing ETL processes by enabling continuous data ingestion and real-time processing.
Unlike traditional batch processing, stream processing handles data as it arrives, allowing for immediate insights and actions.
This approach is important for applications requiring timely data updates, such as real-time analytics and monitoring.
Popular frameworks like Apache Kafka, Apache Flink, and Apache Storm offer powerful tools for efficiently managing and processing streaming data.
These frameworks support a variety of use cases demonstrating the versatility and effectiveness of stream processing in modern ETL architectures.
However, implementing stream processing also comes with challenges, such as ensuring data consistency and managing high-throughput streams requiring careful consideration and planning.
3. Accelerated Data Access with In-Memory Caching
In-memory caching speeds up ETL processes by storing frequently accessed data in memory, reducing the need to repeatedly fetch data from slower disk storage.
This not only improves performance and accelerates data processing tasks but also proves essential for managing frequent read-and-write operations.
Popular solutions like Redis and Memcached are well-suited for this purpose, offering reliable and scalable options for integrating caching into ETL pipelines.
By caching intermediate data, ETL workflows achieve faster data access and reduced latency, thereby improving overall efficiency.
To effectively leverage in-memory caching, it’s essential to choose the right caching strategy, implement efficient cache eviction policies, and monitor cache performance closely to ensure optimal results.
This approach not only speeds up data retrieval but also enhances the responsiveness of applications, contributing to a smoother and more efficient data processing experience.
4. Cost-Effective Resource Management with Cloud Autoscaling
Cloud autoscaling plays a crucial role in optimizing ETL workflows by automatically adjusting resource allocation based on workload demands.
This capability ensures that ETL processes have the necessary computing power during peak times while minimizing costs during off-peak periods.
Cloud providers like AWS Auto Scaling and Azure Autoscale offer features that automate resource management, making it easier for organizations to handle fluctuating data volumes without manual intervention.
Implementing autoscaling involves strategies like setting appropriate scaling policies, monitoring usage patterns, and optimizing resource allocation to balance performance and cost-efficiency effectively.
Wrapping Up
Optimizing ETL processes is paramount for businesses managing vast datasets. Continuous monitoring and refinement are key to sustaining optimal ETL performance. Regularly evaluating and optimizing ETL pipelines will ensure that organizations can adapt to changing data volumes, evolving business needs, and advancements in technology.