
Apache Hudi (Hadoop Upserts Deletes and Incrementals) is a powerful framework designed for managing large datasets on cloud storage systems, enabling efficient data ingestion, storage, and retrieval. One of the key features of Hudi is its support for two distinct storage types: Copy-On-Write (COW) and Merge-On-Read (MOR). Each of these storage strategies has unique characteristics and serves different use cases. In this blog, we will explore COW and MOR.
Prerequisites
Before you begin, ensure you have the following installed on your local machine:
- Docker
- Docker Compose
Local Setup
To set up Apache Hudi locally, follow these steps:
- Clone the Repository:
git clone https://github.com/dnisha/hudi-on-localhost.git cd hudi-on-localhost
- Start Docker Compose:
docker-compose up -d
- Access the Notebooks:
- Open your browser and navigate to http://localhost:8888 for the Jupyter Notebook.
- Also, open http://localhost:9001/login for MinIO.
Username: minioadmin Password: minioadmin
What is Copy-On-Write (COW)?
Copy-On-Write (COW) is a storage type in Apache Hudi that allows for atomic write operations. When data is updated or inserted:
- Hudi creates a new version of the entire data file.
- The existing data file remains unchanged until the new file is successfully written.
This ensures that the operation is atomic, meaning it either completely succeeds or fails without partial updates.
Steps to Evaluate COW
-
Open the Notebook:
- In your browser, navigate to hudi_cow_evaluation.ipynb.
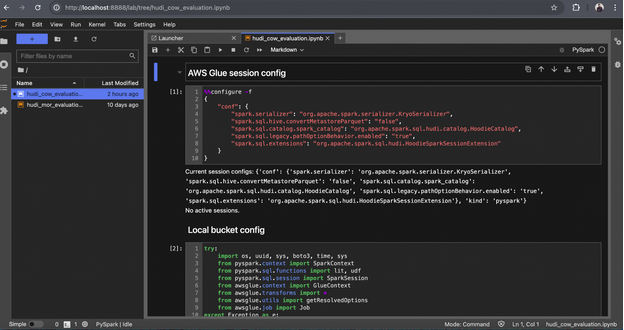
2. Run Configuration Code:
- Execute all configuration-related code in the notebook.
- Ensure you specify the COPY_ON_WRITE table type, as shown in the provided image.
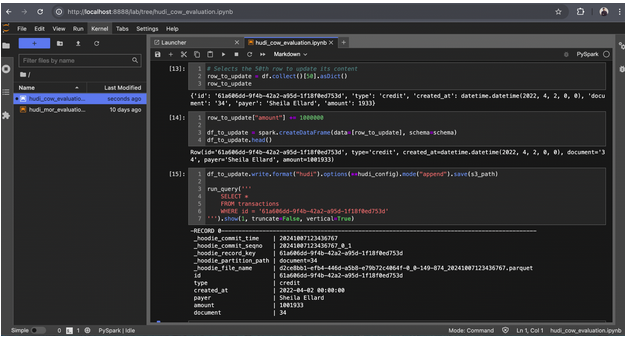
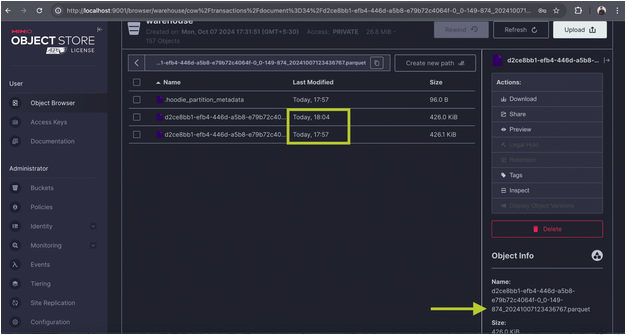
3. Updating a Record:
a. Focus on updating a record in the 34 partition of the COW bucket.
b. Since you are using the COPY_ON_WRITE table type, a new Parquet file will be created for this update. You can find this file in the bucket located at warehouse/cow/transactions/document=34. Open
What is Merge-On-Read (MOR)?
Merge-On-Read (MOR) is an alternative storage type in Apache Hudi that employs a different approach to data management. Here’s how it works:
- Base Parquet Files and Log Files: In MOR, Hudi maintains a combination of base Parquet files alongside log files that capture incremental changes.
- On-the-Fly Merging: When a read operation is executed, Hudi merges the base files and log files in real-time, providing the most up-to-date view of the data.
This approach allows for efficient handling of updates and inserts while enabling faster read operations, as the system does not need to rewrite entire files for every change.
Steps to Evaluate MOR
1. Open the Notebook:
- In your browser, navigate to hudi_mor_evaluation.ipynb.
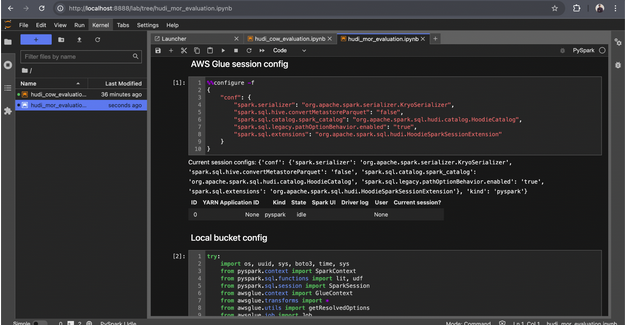
2. Run Configuration Code:
- Execute all configuration-related code in the notebook.
- Ensure you specify the MERGE_ON_READ table type, as shown in the provided image.
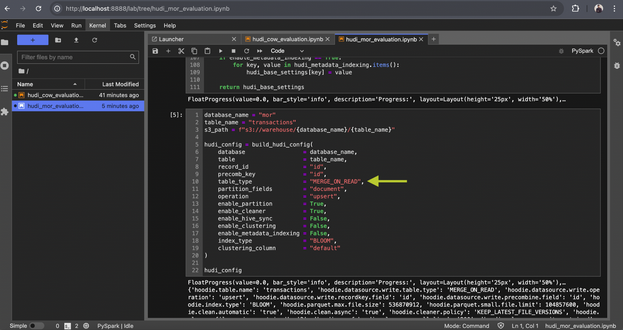
-
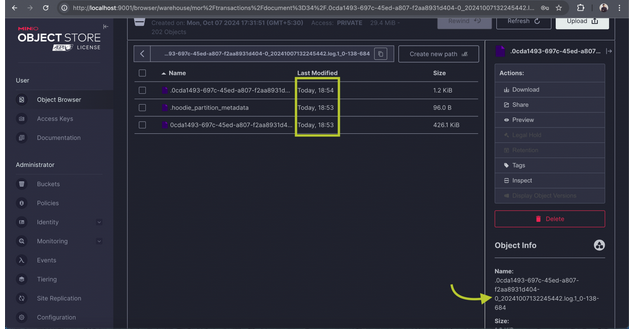
Updating a Record:
- Focus on updating a record in the 34 partition of the MOR bucket.
- Since you are using the MERGE_ON_READ table type, a new row-based file (e.g., Avro) will be created for this update. You can find this file in the bucket located at warehouse/mor/transactions/document=34.
Choosing Between COW and MOR
The choice between COW and MOR in Apache Hudi largely depends on your specific requirements:
- Read vs. Write Frequency: If your workload is read-heavy, COW may be the better choice due to its optimized read performance. Conversely, for write-heavy applications where data is ingested frequently, MOR can handle the load more efficiently.
- Data Consistency: If your application requires strong consistency and atomicity during writes, COW is preferable. MOR is better suited for scenarios where eventual consistency is acceptable.
- Use Case: For analytical workloads and batch processing, COW shines. MOR is often the way to go for real-time data processing and streaming applications.
OpsTree is an End-to-End DevOps Solution Provider.
Connect with Us