
Transform your data landscape with powerful, flexible, and flexible data pipelines. Learn the data engineering strategies needed to effectively manage, process, and derive insights from comprehensive datasets.. Creating robust, scalable, and fault-tolerant data pipelines is a complex task that requires multiple tools and techniques.
Unlock the skills of building real-time stock market data pipelines using Apache Kafka. Follow a detailed step-by-step guide from setting up Kafka on AWS EC2 and learn how to connect it to AWS Glue and Athena for intuitive data processing and insightful analytics.
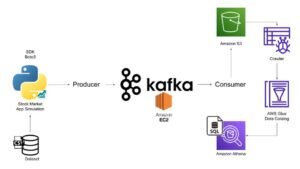
Real-Time Stock Market Data Pipeline Architecture
The architecture for this project consists of the following components:
- Stock Market Data Simulator (Producer): A Python-based stock market simulation app generates real-time stock market data and uses Kafka to produce this data.
- Kafka (Message Broker): Kafka acts as the message broker running on an EC2 instance, which processes and stores real-time streams of data from the producer.
- AWS (Consumers): The real-time stock data is consumed and stored in Amazon S3, cataloged with AWS Glue, and queried using Amazon Athena.
Setup
-
EC2 Instance (Ubuntu/ Amazon Linux): An AWS EC2 instance for running Kafka.
-
Java: Ensure that Java is installed (required by Kafka).
sudo apt install java-1.8.0-openjdk
java -version
Apache Kafka: Download and install Kafka on your EC2 instance.
wget https://downloads.apache.org/kafka/3.8.0/kafka_2.13-3.8.0.tgz
tar -xvf kafka_2.13-3.8.0.tgz
cd kafka_2.13-3.8.0
Kafka Setup Step 1:
Starting ZooKeeper
Kafka requires ZooKeeper for managing its clusters. Start ZooKeeper with the following command:
bin/zookeeper-server-start.sh config/zookeeper.properties
Step 2: Starting Kafka Broker
bin/kafka-server-start.sh config/server.properties
Make sure to modify server.properties to point to your public EC2 IP for external access.
sudo vi config/server.properties
# Modify 'ADVERTISED_LISTENERS' to the public IP of the EC2 instance
Kafka Topic Creation
To create a topic for our stock market data, use the following command:
bin/kafka-topics.sh --create --topic stock_market_data --bootstrap-server {EC2_Example_IP:9092} --replication-factor 1 --partitions 1
Producer Setup
bin/kafka-console-producer.sh --topic stock_market_data --bootstrap-server {EC2_Example_IP:9092}
Consumer Setup
bin/kafka-console-consumer.sh --topic stock_market_data --bootstrap-server {EC2_Example_IP:9092}
[ FInd More about: Real-Time Data Processing ]
AWS Integration for Data Processing
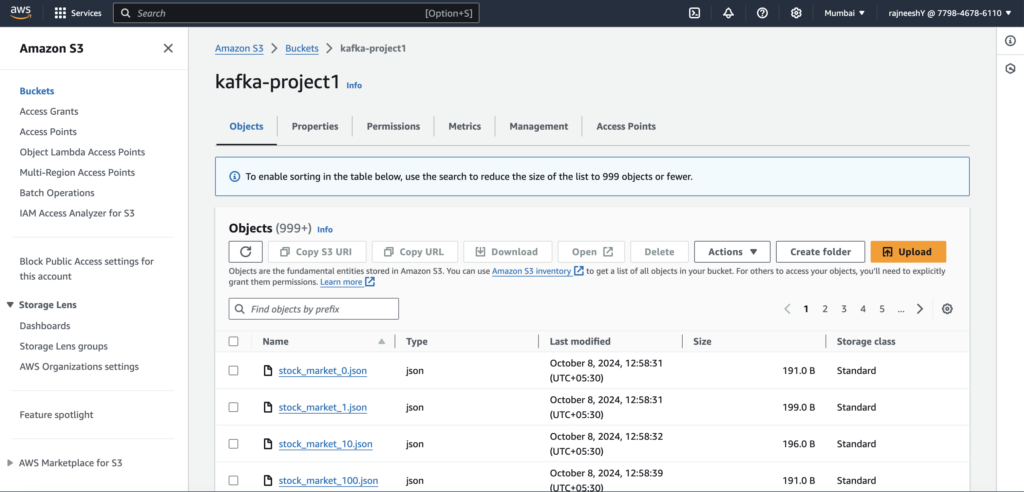
Amazon S3 (Storage) The consumer will push the stock market data into an S3 bucket for further analysis.
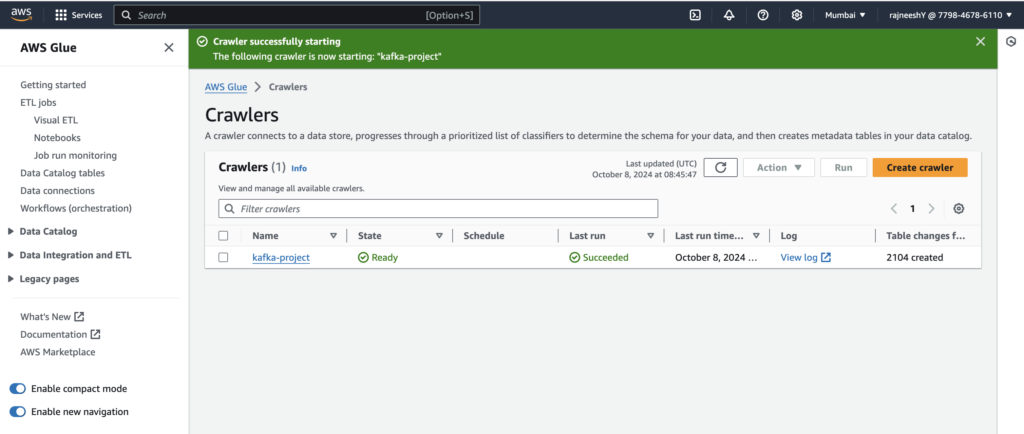
AWS Glue (Data Cataloging)
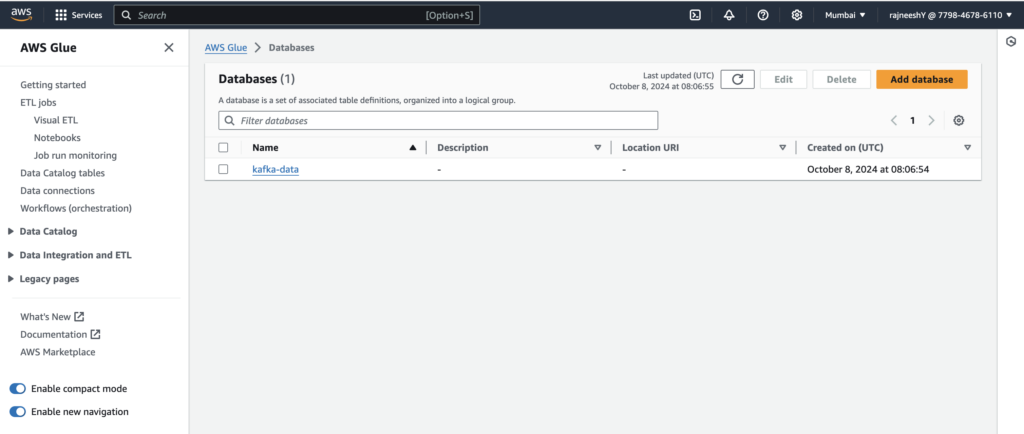
Set up an AWS Glue crawler to scan the S3 bucket and catalog the stock market data. This enables us to query the data using AWS Athena.
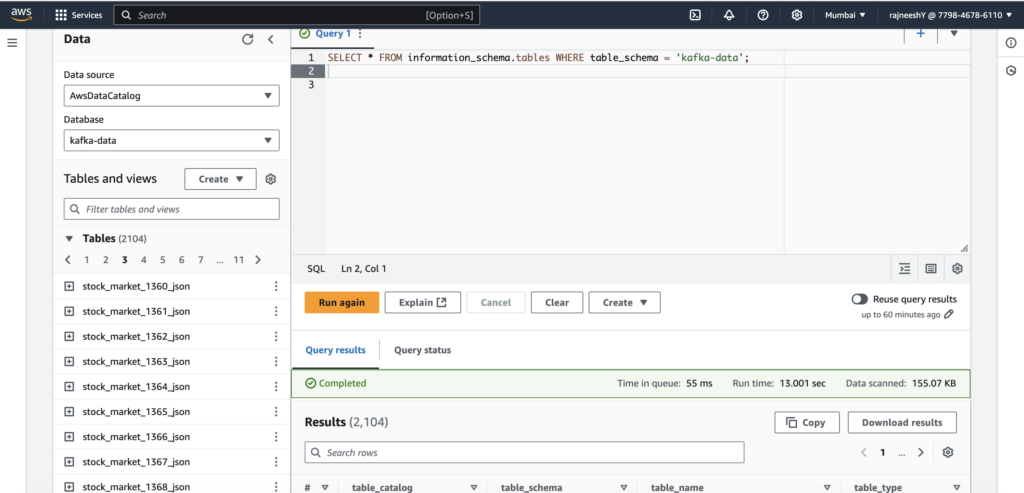
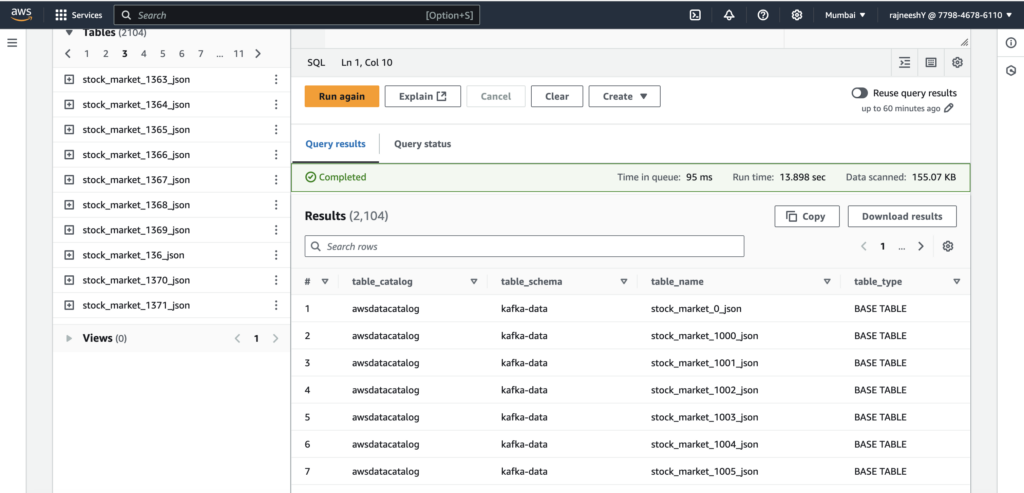
Amazon Athena (Query Engine)
Use Amazon Athena to query the stock market data stored in S3. With Glue providing the schema, Athena allows us to run SQL queries on the ingested real-time data.
Conclusion
This blog demonstrates the real-time data pipeline for stock market data using Kafka as the backbone for streaming data and AWS services for storage, cataloging, and querying. By leveraging Kafka, we can ensure high-throughput, fault-tolerant data streams, while AWS Glue and Athena enable scalable and serverless data analytics.