!!!! The Reset button !!!!
Anyone who has recently used the Google Compute Engine for creating the VM instances will be aware of the reset button available.
Since I wasn’t very much sure of it , I just clicked it without much know-how . This resulted in making all the servers to their original state as they were freshly build and which is certainly a very bad thing for us.
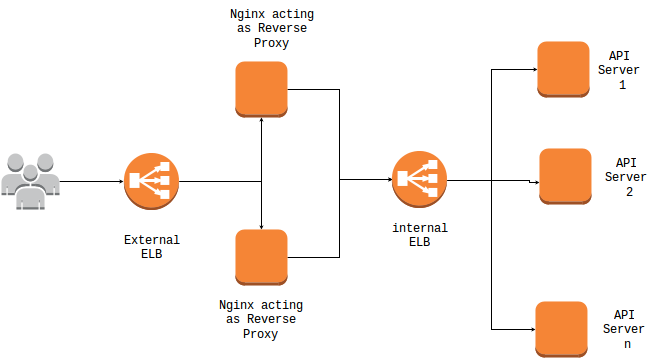
But , we had puppet that we used to create the whole infrastructure as it is . All the modules we had used and changes we made were committed to GitHub repo and this certainly was a boon to us, else we have to sit whole day long for making those changes on the servers.
Just in couple of minutes the new instances were created using the compute engine-create group instance feature. We did installation of the foreman and git on one of the servers and set up the puppet clients agents accordingly . This took around 15 more crucial minutes and then cloned our GitHub repo which contains all the necessary modules and configurations required for the rest of infrastructure.
These are the conditions where Configuration Management Tools like Puppet come in picture and help us get on the track in the shortest possible manner.
It was a hectic day but definitely made us learn several important aspects. Using puppet for maintain the infrastructure is really important now days. It is reliable,efficient and fast for deploying configurations on the servers and making ready for the production work load.