
As businesses start to use big data, they often face big challenges in managing, storing, and analyzing the large amounts of information they collect.
Traditional data modeling techniques which were designed for more structured and predictable data environments, can lead to performance issues, scalability problems, and inefficiencies when applied to big data.
The mismatch between traditional methods and the dynamic nature of big data causes these issues, resulting in slower decision-making, higher costs, and the inability to fully leverage data.
For many organizations, these challenges result in slower decision-making, higher costs, and the inability to fully use their data.
In this blog, we will explore the sophisticated data modeling techniques designed for big data applications.
What is Data Modeling?
Data modeling is a complex process that involves creating a visual representation of data and its interrelationships. It serves as a basic guide for structuring, storing, and accessing data, and ensures that management practices are consistent and clear.
By defining data elements and their relationships, teams can organize information more effectively, thereby improving storage, retrieval, and analysis. This ultimately increases performance and helps in making better decisions.
[ Are you looking: Data engineering services provider]
The Challenges of Big Data
Big data is characterized by its three defining features: volume, velocity, and variety. Understanding these aspects is crucial to addressing the unique challenges they present.
Volume
The sheer amount of data generated today is staggering. Organizations collect data from multiple sources, including customer transactions, social media interactions, sensors, and more. Managing this enormous volume of data requires storage solutions that can scale and data models that can efficiently handle large datasets without compromising performance.
Velocity
The speed at which data is generated and needs to be processed is another major challenge. Real-time or near-real-time data processing is often required to derive actionable insights promptly. Traditional data models, which are designed for slower, batch processing, often fail to keep up with the rapid influx of data, leading to bottlenecks and delays.
Variety
Big data comes in various formats, from structured data in databases to unstructured data such as text, images, and videos. Integrating and analyzing these diverse data types requires flexible models that accommodate different formats and structures. Traditional models, which are typically rigid and schema-dependent, struggle to adapt to this variety.
Advanced data modeling techniques, such as dimensional modeling, data vault, and star schema design, are specifically developed to address these limitations. With these approaches, organizations can overcome the limitations of traditional models, ensuring their big data applications are robust, scalable, and efficient.

Top 3 Big Data Modelling Approaches
1. Dimensional Modeling
Dimensional modeling is a design concept used to structure data warehouses for efficient retrieval and analysis. It is primarily utilized in business intelligence and data warehousing contexts to make data more accessible and understandable for end-users. This model organizes data into fact and dimension tables, facilitating easy and fast querying.
Key Components
- Facts: These are central tables in a dimensional model containing quantitative data for analysis, such as sales revenue, quantities sold, or transaction counts.
- Dimensions: These tables hold descriptive attributes related to facts, such as time, geography, product details, or customer information.
- Measures: Measures are the numeric data in fact tables that are analyzed, like total sales amount or number of units sold.
Dimensional modeling simplifies the query process as it organizes data in a way that is intuitive for reporting tools, leading to faster query performance. The structure of dimensional models is straightforward, making it easier for business users to understand the data relationships and derive insights without needing in-depth technical knowledge.
2. Data Vault Modeling
Data vault modeling is a database modeling method designed to provide long-term historical storage of data from multiple operational systems. It is highly scalable and adaptable to changing business needs, making it suitable for big data environments.
Key Concepts
Hubs: Represent core business entities (e.g., customers, products) and contain unique identifiers.
Links: Capture relationships between hubs (e.g., sales transactions linking customers to products).
Satellites: Store descriptive data and track changes over time (e.g., customer address changes).
The modular nature of the data vault allows the easy addition of new data sources and adapts to changing business requirements. It supports the integration of data from multiple sources by providing a consistent and stable data model.
Star Schema Design
In data warehousing and business intelligence, star schema is a widely used data modeling technique for organizing data in a way that optimizes query performance and ease of analysis. It’s characterized by a central fact table surrounded by multiple dimension tables, resembling a star shape.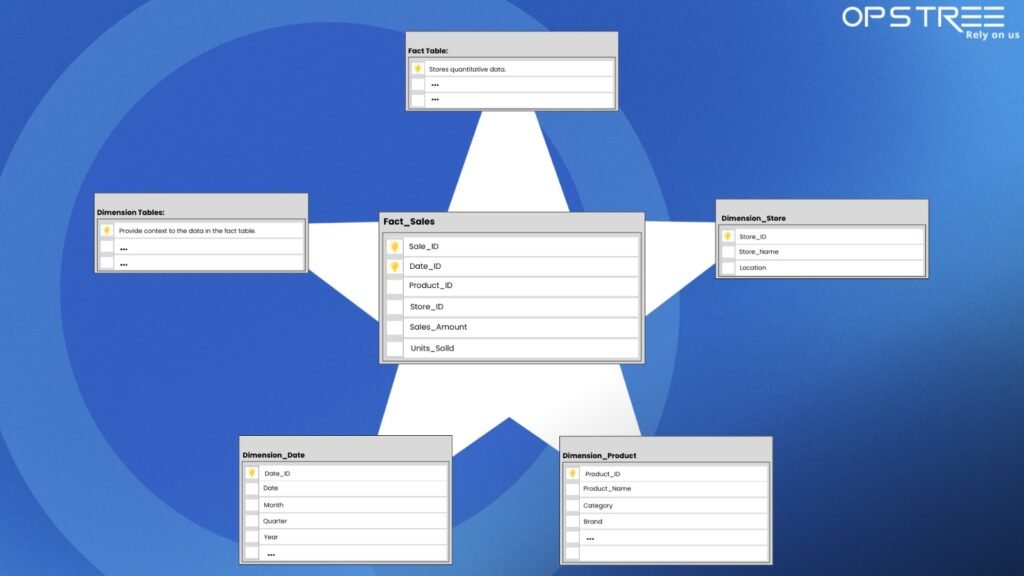 Key Components
Key Components
- Fact Tables: Contain quantitative data for analysis (e.g., sales amounts, units sold).
- Dimension Tables: Store descriptive attributes related to the fact data (e.g., dates, customer information, product details).
Star schemas can handle large volumes of data by optimizing storage and retrieval processes. The simple structure of star schemas enables efficient querying and data retrieval.
[ Good Read: How to Implement Data Replication across multi-cloud environments]
Comparing These Three Data Modelling Techniques
When comparing dimensional modeling, data vault modeling, and star schema design, each technique presents unique strengths and weaknesses. These factors influence their suitability for various big data applications.
Dimensional Modeling simplifies complex data into an easily understandable format, enhancing query performance and usability for business users. However, it may face challenges with handling complex relationships and adapting quickly to changing business needs.
Data Vault Modeling provides exceptional scalability and flexibility, making it ideal for environments with large and intricate data requirements, such as financial systems. Yet, its implementation and maintenance can be more complex compared to other models.
Star Schema Design optimizes query performance and supports large data volumes, particularly in data warehousing applications like retail analytics. However, it may involve storing redundant data, which can impact storage efficiency.
Wrapping Up
When choosing a data modeling technique, consider factors such as data complexity, performance requirements, and specific business needs. This thoughtful evaluation ensures that organizations can effectively leverage the strengths of each approach to meet their big data challenges while minimizing complexity.
FAQs
1. What is data modeling in the context of big data applications?
In the field of big data, data modeling aims to shape how we understand and interact with massive datasets, often fraught with complexity and inconsistency.It lays out the framework for structuring the data, clarifying relationships, and deciding on formats, all of which are crucial for organizing the data and preparing it for analysis. This ultimately leads to the creation of scalable and efficient big data applications.
2. Why is data modeling important for modern data-driven applications?
It establishes a clear and consistent approach to managing large amounts of data, making it easier to store and process. This clarity not only enhances decision-making but also protects data integrity, enabling organizations to extract valuable insights from even the most complex datasets.
3. What are the key challenges of data modeling in big data environments?
Data modeling in big data settings presents several obstacles, such as dealing with huge data volumes, high speed of data generation, and diverse data types. Ensuring that models can scale effectively, managing semi-structured or unstructured data, and integrating data from different sources without compromising performance are some of the key challenges.
4. How does NoSQL data modeling support real-time business decisions?
NoSQL models (such as document or key-value stores) support high-speed data ingestion and querying — which is critical for real-time applications such as fraud detection, recommendation engines, or live dashboards, where instant decision making is critical.
5. What are some commonly used data modeling techniques in big data?
Several techniques are frequently used in big data contexts, including hierarchical modeling, network modeling, and entity-relationship (ER) modeling. Additionally, star and snowflake schemas are commonly utilized in online analytical processing (OLAP) systems, along with NoSQL modeling approaches that cater to document stores, wide-column databases, or graph databases.