
Introduction
In this blog, we’ll explore the powerful concept of Retrieval-Augmented Generation (RAG) and how it enhances the capabilities of large language models by integrating real-time, external knowledge sources. You’ll also learn how to build an end-to-end application that leverages this approach for practical use.
We’ll begin by understanding what RAG is, how it works, and why it’s gaining popularity for building more accurate and context-aware AI solutions. RAG combines the strengths of information retrieval and text generation, enabling language models to reference external, up-to-date knowledge bases beyond their original training data, making outputs more reliable and factually accurate.
As a practical demonstration, we’ll walk through building a custom RAG application that can intelligently query information from your own PDF documents. To achieve this, we’ll use the AWS Bedrock Llama 3 8B Instruct model, along with the LangChain framework and Streamlit for a user-friendly interface.
Key Technologies For End-to-End RAG Solution
1. Streamlit:
a. Interactive front–end for the application.
b. Simple yet powerful framework for building Python web
apps.
2. LangChain:
a. Framework for creating LLM–powered workflows.
b. Provides seamless integration with AWS Bedrock.
3. AWS Bedrock:
a. State–of–the–art LLM platform.
b. Powered by the highly efficient Llama 3 8B Instruct model.
1. Create a vector store
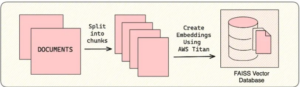
Load–>Transform–>Embed.
We will use the FAISS vector database, to efficiently handle queries,
the text is tokenized and embedded into a vector store using FAISS
(Facebook AI Similarity Search).
2. Query vector store “Retrieve most similar”
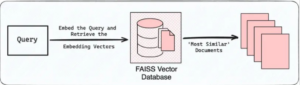
query and retrieve the embedding vector that is most similar to the embedded query. A vector stores embed data and performs a
3. Response generation using LLM:
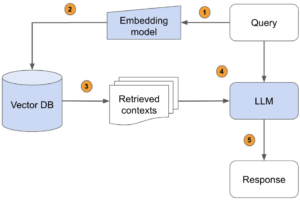
Imports and Setup
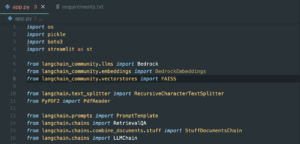
- os: Used for handling file paths and checking if files exist on disk.
- pickle: A Python library for serializing and deserializing Python objects to store/retrieve embeddings.
- boto3: AWS SDK for Python; used to interact with Amazon Bedrock services.
- streamlit: A library for creating web apps for data science and machine learning projects.
- Bedrock: Used to interact with Amazon Bedrock for deploying large language models (LLMs).
- Bedrock Embeddings: To generate embeddings using Bedrock models.
- FAISS: A library for efficient similarity search and clustering of dense vectors.
- Recursive Character Text Splitter: Splits large text into manageable chunks for embedding generation.
- Pdf Reader: From PyPDF2, used to extract text from PDF files.
- Prompt Template: Defines the structure of the prompt for the LLM.
- Retrieval QA: Combines a retriever and a chain to create a question–answering system.
- Stuff Documents Chain: Combines multiple documents into a single context for answering questions.
- LLM Chain: A chain that interacts with a language model using a defined prompt.
- Initialize Bedrock and Embedding Models

- Initializes an Amazon Bedrock client using boto3 to interact with Bedrock services.
- Initializes the bedrock titan embedding model amazon.titan–embed–text–v1 for generating vector embeddings of text.
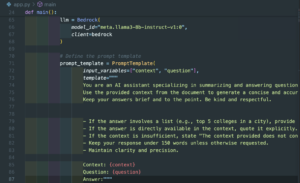
Define Bedrock LLM and Prompt template
The application begins by initializing the Amazon Bedrock Large Language Model (LLM) using a specified model_id. A custom prompt template is also defined to guide the AI assistant on how to generate responses effectively.
This template outlines specific formatting instructions, such as:
- Providing answers in a clear and concise manner
- Using bullet points for lists
- Maintaining a respectful and informative tone
Additionally, it includes fallback guidelines for cases where context is limited or when responses must adhere to a defined word count. This structured approach ensures the output is both accurate and user-friendly.
Now, let’s setup Amazon Bedrock.

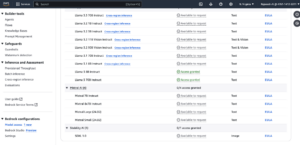
Click on Model Access on the left navigation menu. It will show the list of models available with Bedrock, as of today.
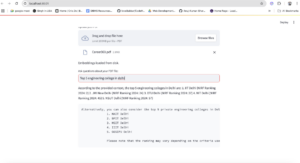
This blog demonstrates the potential of integrating AWS Bedrock, LangChain, and Streamlit to develop a smart, user-friendly Retrieval-Augmented Generation (RAG) solution. Whether you’re a developer, data scientist, or AI enthusiast, this tech stack provides a solid foundation for building next-generation, context-aware AI applications.