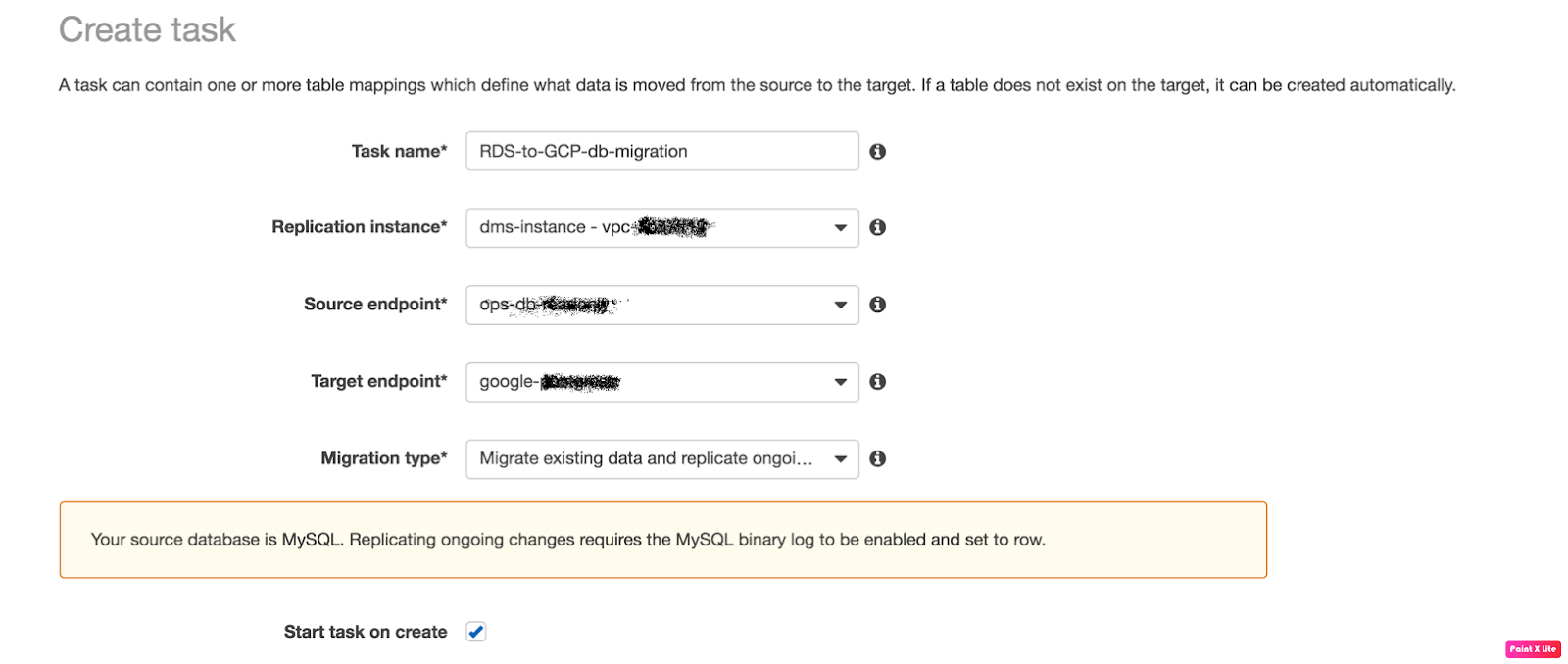
In this blogpost, we will see how to get started with packer. We will cover installation, writing a template for creating AWS AMI. To get the basic understanding of how packer works, You can refer to our previous blog “Intro To Packer”.
Installation
- Official method to download packer as precompiled binary, packer does not provide system packages and neither they have any plan to make it avail as such:-$curl -L https://releases.hashicorp.com/packer/1.4.0/packer_1.4.0_linux_amd64.zip
- After downloading the binary unzip it to the location you want to keep it. If you want it to be installed such that it can be used by system-wide users, do not unzip in user space $sudo unzip packer_1.4.0_linux_amd64.zip -d /usr/local/packer
- After unzipping the package, the directory should contain a single binary program called packer .
- The final step to installation is to make sure the directory you installed Packer to is set on the PATH, so that it can be used using a command line. Open the /etc/environment and append the below line to the end of the file export PATH=”$PATH:/usr/local/packer” After adding the line into the file to let the change reflect source the environment file $source /etc/environment
- Verify the installation by firing packer command or simply check its version by $packer –version . You should see the version of packer as an output.
Once installed, running packer is as simple as packer build , which will take the build-file and run the steps we provide within. Let’s get started with a simple build file.
Setting Up Stage

As we are building an image for AWS cloud, there are certain prerequisites which need to be taken care of.
You should have IAM user who has access to create and destroy ec2 instance, create an AMI, create and destroy security groups etc. You can find sample IAM policy for packer user in sample minimum IAM user policy for Packer.
After setting up your IAM user for packer, generate the access key and id and save it.
Now having noted the key, you can either directly use it in your template (which is not suggested) or you can configure it as an environment variable or the AWS CLI config on which you have the packer installed.
I have configured it with AWS CLI config so I did not have to define in variable section or in the builder section. You can also pass your access keys as variable as an option while running packer build command.
Here we will be installing apache webserver in the image. I have named this json file as httpd.json and used httpd.sh script to install httpd under provisioner section.

Below is the sample httpd.json file
|
{
“variables”: {
“ami_id”: “ami-0a574895390037a62”, “app_name”: “httpd” }, “builders”: [{ “type”: “amazon-ebs”, “region”: “ap-south-1”, “vpc_id”: “vpc-df95d4b7”, “subnet_id”: “subnet-175b2d7f”, “source_ami”: “{{user `ami_id`}}”, “instance_type”: “t2.micro”, “ssh_username”: “ubuntu”, “ami_name”: “PACKER-DEMO-{{user `app_name` }}”, “tags”: { “Name”: “PACKER-DEMO-{{user `app_name` }}”, “Env”: “DEMO” } “provisioners”: [ }
|
Below is the simple httpd.sh
|
#!/bin/bash sudo apt-get update
|
First Validate your template by firing below command:-
|
packer validate httpd.json
|
You should get the output as a success, or as an error indicating the line number.
Now run packer build to build your image:-
|
packer build httpd.json
|
After a successful build, you will get AMI id as output and success message.
|
==> amazon-ebs: Prevalidating AMI Name: PACKER-DEMO-httpd
amazon-ebs: Found Image ID: ami-0a574895390037a62 ==> amazon-ebs: Creating temporary keypair: packer_5cd559df-84ce-ff8a-fa93-0c4477d988e4 ==> amazon-ebs: Creating temporary security group for this instance: packer_5cd559e2-ea81-be15-b94a-c28493c0d3ff ==> amazon-ebs: Authorizing access to port 22 from [0.0.0.0/0] in the temporary security groups… ==> amazon-ebs: Launching a source AWS instance… ==> amazon-ebs: Adding tags to source instance amazon-ebs: Adding tag: “Name”: “Packer Builder” amazon-ebs: Instance ID: i-06ed051a3435865c4 ==> amazon-ebs: Waiting for instance (i-06ed051a3435865c4) to become ready… ==> amazon-ebs: Using ssh communicator to connect: *.*.*.* ==> amazon-ebs: Waiting for SSH to become available… ==> amazon-ebs: Connected to SSH! ==> amazon-ebs: Stopping the source instance… amazon-ebs: Stopping instance ==> amazon-ebs: Waiting for the instance to stop… ==> amazon-ebs: Creating AMI PACKER-DEMO-httpd from instance i-06ed051a3435865c4 amazon-ebs: AMI: ami-0ce41081a3b649374 ==> amazon-ebs: Waiting for AMI to become ready… ==> amazon-ebs: Adding tags to AMI (ami——)… ==> amazon-ebs: Tagging snapshot: snap-0ee3ce80ec289ed24 ==> amazon-ebs: Creating AMI tags amazon-ebs: Adding tag: “Name”: “PACKER-DEMO-httpd” amazon-ebs: Adding tag: “Env”: “DEMO” ==> amazon-ebs: Creating snapshot tags ==> amazon-ebs: Terminating the source AWS instance… ==> amazon-ebs: Cleaning up any extra volumes… ==> amazon-ebs: No volumes to clean up, skipping ==> amazon-ebs: Deleting temporary security group… ==> amazon-ebs: Deleting temporary keypair… Build ‘amazon-ebs’ finished.==> Builds finished. The artifacts of successful builds are: –> amazon-ebs: AMIs were created: ap-south-1: ami——————–
|
Few things to keep in mind:-

- Packer does not create the image of any running instance, instead, it spins a temporary instance and create the image, post image creation it destroys all the resources which were created by a packer in order to create images.
- Though packer gives us ease of taking machine AMI’s programmatically, purging of an older image should also be kept in mind because AMIs gets stored over s3 and it might add up to your cost.
- Though a rollback becomes a lot easier in immutable infra. It can become a pain in the neck if you frequently make changes in production.
- We cannot expect it to solve all our problems, its only job is to create an image. You will have to decide when to create an image and what post action needs to be taken or deployed after image creation.
I hope the above setup will help you in getting started with it. Later we will discuss how we can use it along with Ansible and Terraform to achieve immutable Infra.
I appreciate any suggestions and comments or any questions/doubts faced while implementing it.