

Recently I was asked to set up a CI- Pipeline for a Spring based application.
I said “piece of cake”, as I have already worked on jenkins pipeline, and knew about maven so that won’t be a problem. But there was a hitch, “pipeline of Gitlab CI“. I said “no problem, I’ll learn about it” with a Ninja Spirit.
So for starters what is gitlab-ci pipeline. For those who have already work on Jenkins and maven, they know about the CI workflow of Building a code , testing the code, packaging, and deploy it using maven. You can add other goals too, depending upon the requirement.
The CI process in GitLab CI is defined within a file in the code repository itself using a YAML configuration syntax.
The work is then dispatched to machines called runners, which are easy to set up and can be provisioned on many different operating systems. When configuring runners, you can choose between different executors like Docker, shell, VirtualBox, or Kubernetes to determine how the tasks are carried out.
What we are going to do?
We will be establishing a CI/CD pipeline using gitlab-ci and deploying artifacts to NEXUS Repository.

Resources Used:
- Gitlab server, I’m using gitlab to host my code.
- Runner server, It could be vagrant or an ec2 instance.
- Nexus Server, It could be vagrant or an ec2 instance.
Before going further, let’s get aware of few terminologies.
- Artifacts: Objects created by a build process, Usually project jars, library jar. These can include use cases, class diagrams, requirements, and design documents.
- Maven Repository(NEXUS): A repository is a directory where all the project jars, library jar, plugins or any other project specific artifacts are stored and can be used by Maven easily, here we are going to use NEXUS as a central Repository.
- CI: A software development practice in which you build and test software every time a developer pushes code to the application, and it happens several times a day.
- Gitlab-runner: GitLab Runner is the open source project that is used to run your jobs and send the results back to GitLab. It is used in conjunction with GitLab CI, the open-source continuous integration service included with GitLab that coordinates the jobs.
- .gitlab-ci.yml: The YAML file defines a set of jobs with constraints stating when they should be run. You can specify an unlimited number of jobs which are defined as top-level elements with an arbitrary name and always have to contain at least the script clause. Whenever you push a commit, a pipeline will be triggered with respect to that commit.
Strategy to Setup Pipeline
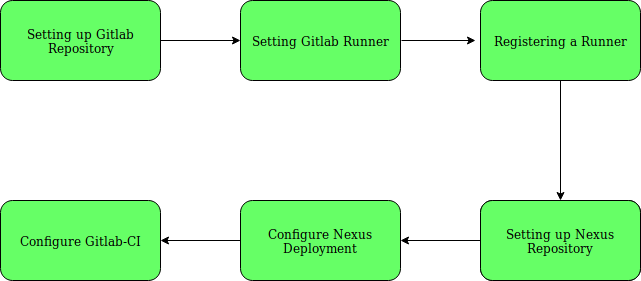
Step-1: Setting up GitLab Repository.
$ cd spring3hibernateapp
$ ls
pom.xml pom.xml~ src
# Now lets start pushing this code to gitlab
$ git remote -v
origin git@gitlab.com:/spring3hibernateapp.git (fetch)
origin git@gitlab.com:/spring3hibernateapp.git (push)
$ git add -A
$ git commit -m "[Master][Add] Adding the code "
$ git push origin master
Step-2: Install GitLab Runner manually on GNU/Linux
$ sudo wget -O /usr/local/bin/gitlab-runner https://gitlab-runner-downloads.s3.amazonaws.com/latest/binaries/gitlab-runner-linux-386
# Give it permissions to execute:
$ sudo chmod +x /usr/local/bin/gitlab-runner
# Optionally, if you want to use Docker, install Docker with:
$ curl -sSL https://get.docker.com/ | sh
# Create a GitLab CI user:
$ sudo useradd --comment 'GitLab Runner' --create-home gitlab-runner --shell /bin/bash
# Install and run as service:
$ sudo gitlab-runner install --user=gitlab-runner --working-directory=/home/gitlab-runner
$ sudo gitlab-runner start
Step-3: Registering a Runner
# Run the following command:
$ sudo gitlab-runner register
Runtime platform arch=amd64 os=linux pid=1742 revision=3afdaba6 version=11.5.0
Running in system-mode.
# Please enter the gitlab-ci coordinator URL (e.g. https://gitlab.com/):
https://gitlab.com/
# Please enter the gitlab-ci token for this runner:
****8kmMfx_RMr****
# Please enter the gitlab-ci description for this runner:
[gitlab-runner]: spring3hibernate
# Please enter the gitlab-ci tags for this runner (comma separated):
build
Registering runner... succeeded runner=ZP3TrPCd
# Please enter the executor: docker, docker-ssh, shell, ssh, virtualbox, docker+machine, parallels, docker-ssh+machine, kubernetes:
docker
# Please enter the default Docker image (e.g. ruby:2.1):
maven
Runner registered successfully. Feel free to start it, but if it's running already the config should be automatically reloaded!
# You can also create systemd service in /etc/systemd/system/gitlab-runner.service.
[Unit]
Description=GitLab Runner
After=syslog.target network.target
ConditionFileIsExecutable=/usr/local/bin/gitlab-runner
[Service]
StartLimitInterval=5
StartLimitBurst=10
ExecStart=/usr/local/bin/gitlab-runner "run" "--working-directory" "/home/gitlab-runner" "--config" "/etc/gitlab-runner/config.toml" "--service" "gitlab-runner" "--syslog" "--user" "gitlab-runner"
Restart=always
RestartSec=120
[Install]
WantedBy=multi-user.target
Step-4: Setting up Nexus Repository
You can setup a repository installing the open source version of Nexus you need to visit Nexus OSS and download the TGZ version or the ZIP version.
But to keep it simple, I used docker container for that.
# Install docker
$ curl -sSL https://get.docker.com/ | sh
# Launch a NEXUS container and bind the port
$ docker run -d -p 8081:8081 --name nexus sonatype/nexus:oss
You can access your nexus now on http://:8081/nexus.
And login as admin with password admin123.
Step-5: Configure the NEXUS deployment
Clone your code and enter the repository
$ cd spring3hibernateapp/
# Create a folder called .m2 in the root of your repository
$ mkdir .m2
# Create a file called settings.xml in the .m2 folder
$ touch .m2/settings.xml
# Copy the following content in settings.xml
<settings xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.1.0 http://maven.apache.org/xsd/settings-1.1.0.xsd"
xmlns="http://maven.apache.org/SETTINGS/1.1.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
central
${env.NEXUS_REPO_USER}
${env.NEXUS_REPO_PASS}
snapshots
${env.NEXUS_REPO_USER}
${env.NEXUS_REPO_PASS}
Username and password will be replaced by the correct values using variables.
# Updating Repository path in pom.xml
central
Central
${env.NEXUS_REPO_URL}central/
snapshots
Snapshots
${env.NEXUS_REPO_URL}snapshots/
Step-6: Configure GitLab CI/CD for simple maven deployment.
.gitlab-ci.yml, to read the definitions for jobs that will be executed by the configured GitLab Runners.- NEXUS_REPO_URL: http://:8081/nexus/content/repositories/
- NEXUS_REPO_USER: admin
- NEXUS_REPO_PASS: admin123
Now it’s time to define jobs in .gitlab-ci.yml and push it to the repo:
image: maven
variables:
MAVEN_CLI_OPTS: "-s .m2/settings.xml --batch-mode"
MAVEN_OPTS: "-Dmaven.repo.local=.m2/repository"
cache:
paths:
- .m2/repository/
- target/
stages:
- build
- test
- package
- deploy
codebuild:
tags:
- build
stage: build
script:
- mvn compile
codetest:
tags:
- build
stage: test
script:
- mvn $MAVEN_CLI_OPTS test
- echo "The code has been tested"
Codepackage:
tags:
- build
stage: package
script:
- mvn $MAVEN_CLI_OPTS package -Dmaven.test.skip=true
- echo "Packaging the code"
artifacts:
paths:
- target/*.war
only:
- master
Codedeploy:
tags:
- build
stage: deploy
script:
- mvn $MAVEN_CLI_OPTS deploy -Dmaven.test.skip=true
- echo "installing the package in local repository"
only:
- master
Now add the changes, commit them and push them to the remote repository on gitlab. A pipeline will be triggered with respect to your commit. And if everything goes well our mission will be accomplished.
Note: You might get some issues with maven plugins, which will need to managed in pom.xml, depending upon the environment.
In this blog, we covered the basic steps to use a Nexus Maven repository to automatically publish and consume artifacts.