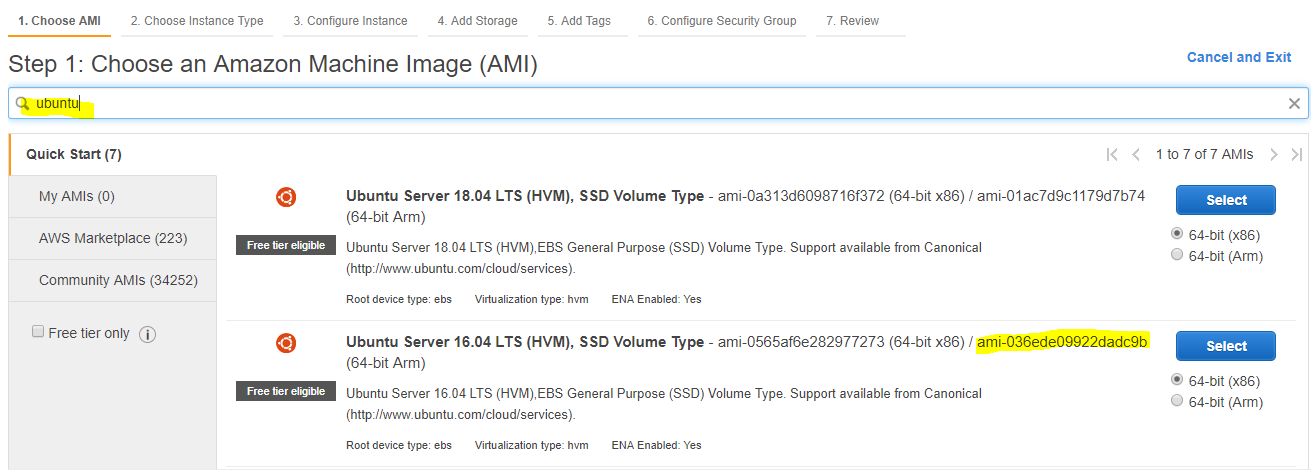
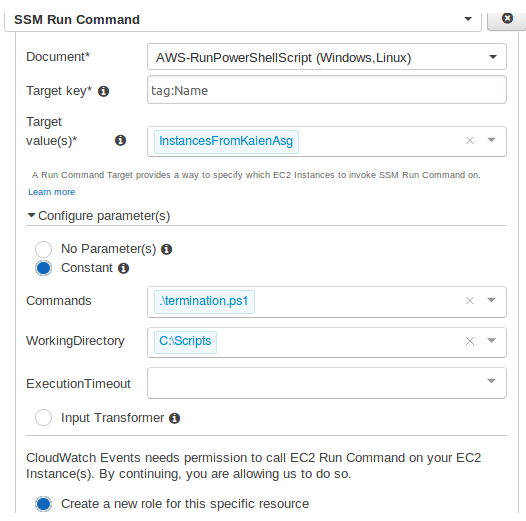
Git Inside-Out
Git is basically a file-system where you can retrieve your content through addresses. It simply means that you can insert any kind of data into git for which Git will hand you back a unique key you can use later to retrieve that content. We would be learning #gitinsideout through this blog
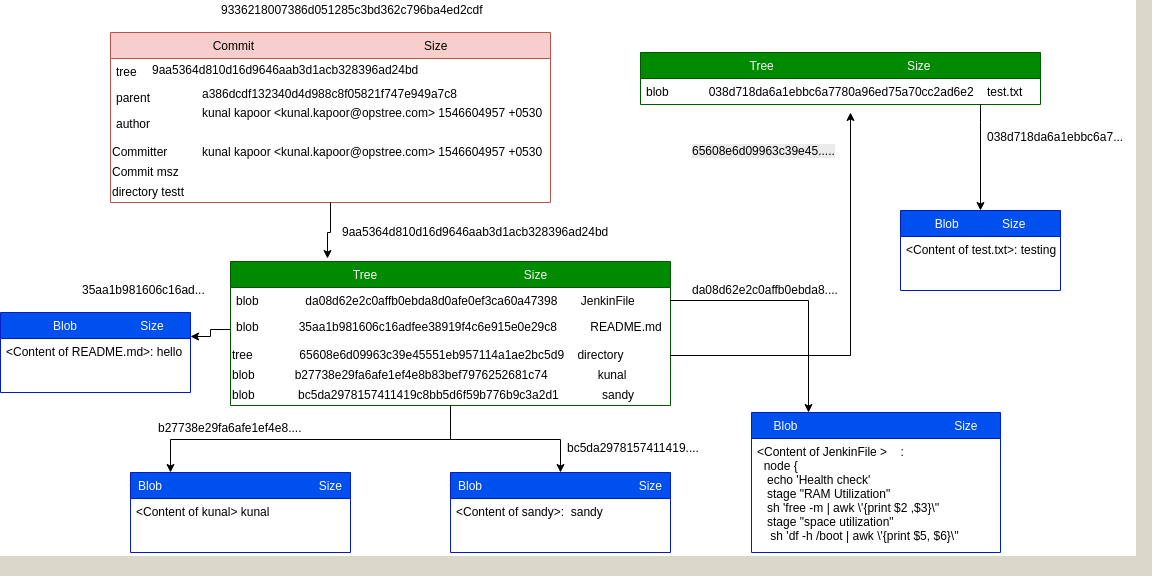
The Git object model has three types: blobs (for files), trees (for folder) and commits.
Objects are immutable (they are added but not changed) and every object is identified by its unique SHA-1 hash
A blob is just the contents of a file. By default, every new version of a file gets a new blob, which is a snapshot of the file (not a delta like many other versioning systems).
A tree is a list of references to blobs and trees.
A commit is a reference to a tree, a reference to parent commit(s) and some decoration (message, author).
Then there are branches and tags, which are typically just references to commits.
Git stores the data in our .git/objects directory. After initialising a git repository, it automatically creates .git/objects/pack and .git/objects/info with no regular file. After pushing some files, it would reflect in the .git/objects/ folder
OBJECT Blob
blob stores the content of a file and we can check its content by command
git cat-file -p
or git show
OBJECT Tree
A tree is a simple object that has a bunch of pointers to blobs and other trees – it generally represents the contents of a directory or sub-directory.
We can use git ls-tree to list the content of the given tree object
OBJECT Commit
The “commit” object links a physical state of a tree with a description of how we got there and why.
A commit is defined by tree, parent, author, committer, comment
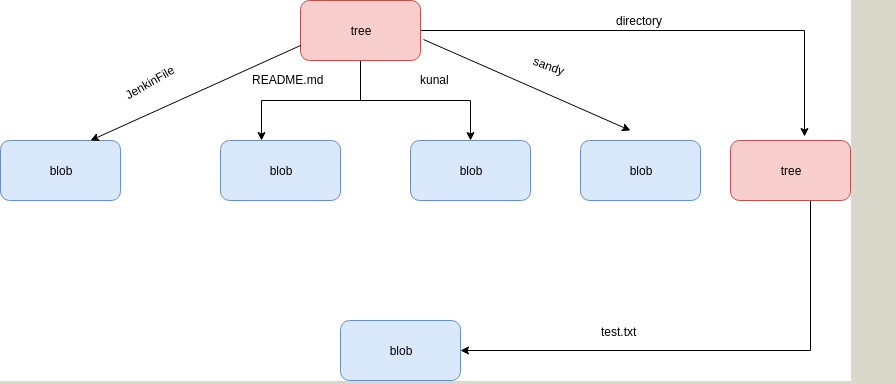
All three objects ( blob,Tree,Commit) are explained in details with the help of a pictorial diagram.
Often we make changes to our code and push it to SCM. I was doing it once and made multiple changes, I was thinking it would be great if I could see the details of changes through local repository itself instead to go to a remote repository server. That pushed me to explore Git more deeply.
I just created a local remote repository with the help of git bare repository. Made some changes and tracked those changes(type, content, size etc).
Below example will help you understand the concept behind it.
Suppose we have cloned a repository named kunal:
Inside the folder where we have cloned the repository, go to the folder kunal then:
cd kunal/.git/
I have added content(hello) to readme.md and made many changes into the same repository as:
adding README.md
updating Readme.md
adding 2 files modifying one
pull request
commit(adding directory).
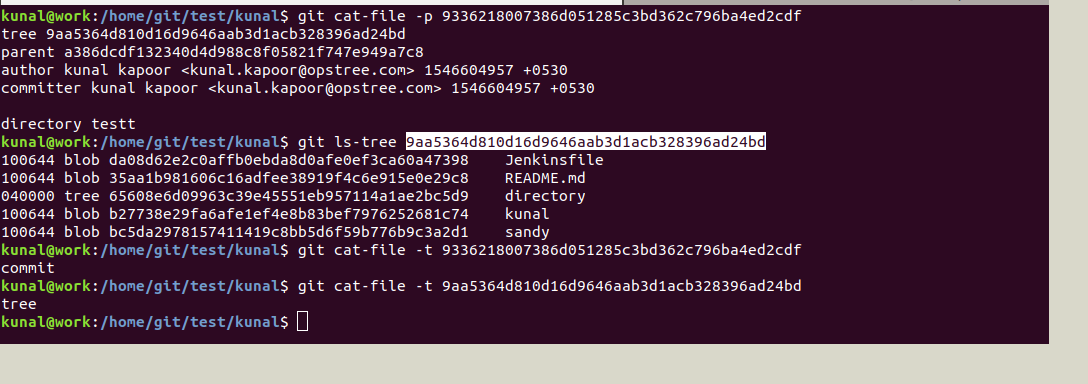
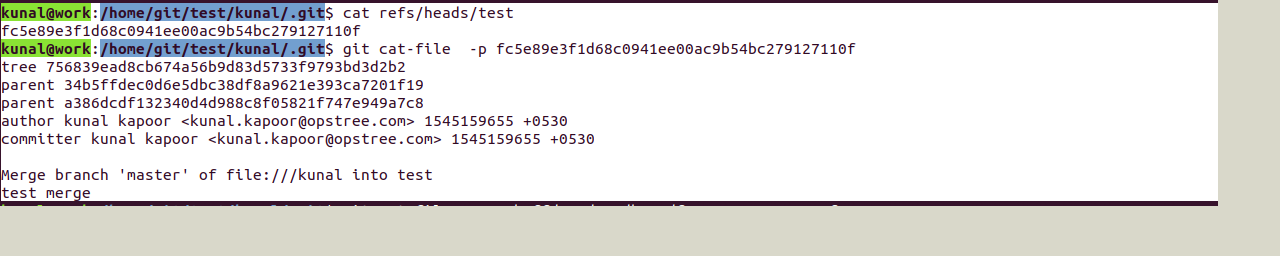
Go to the refer folder inside .git and take the SHA value for the master head:

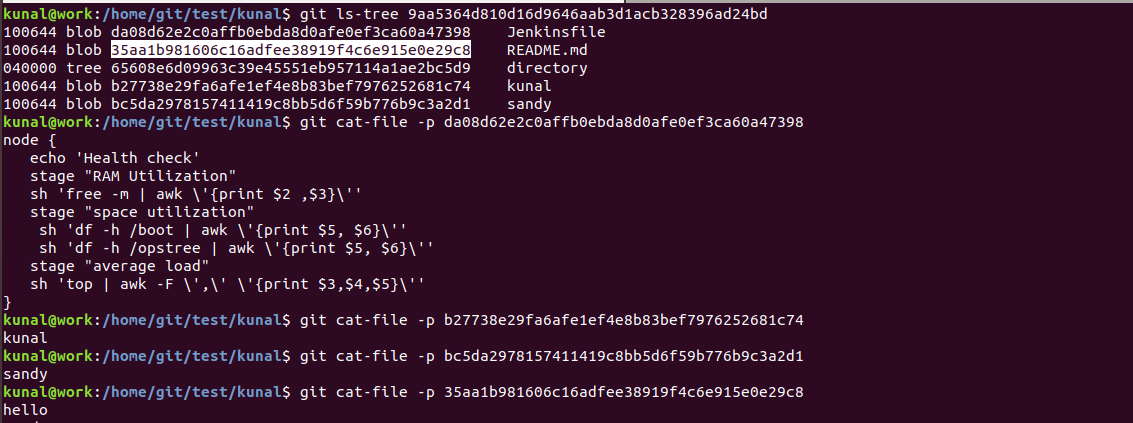
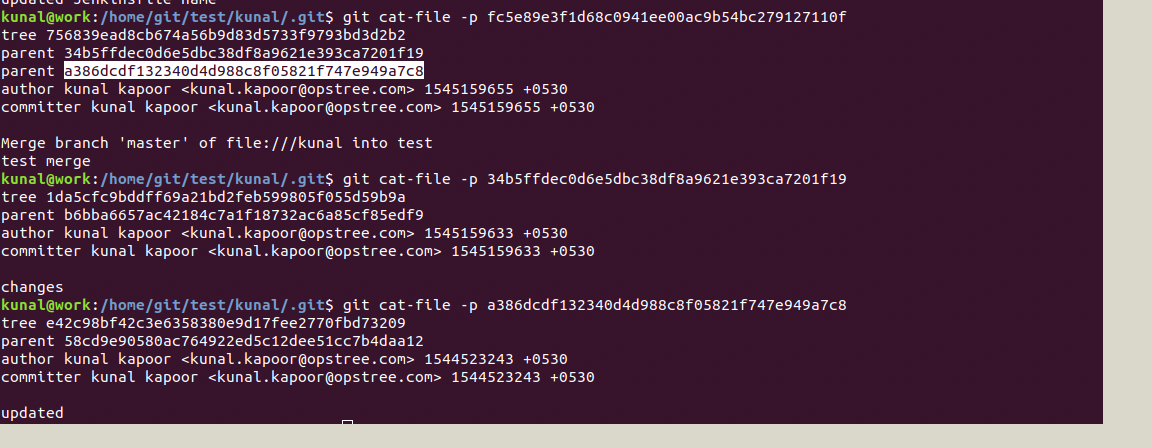
This commit object we can explore further with the help of cat-file which will show the type and content of tree and commit object:
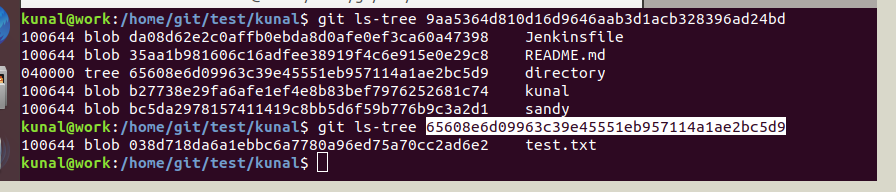
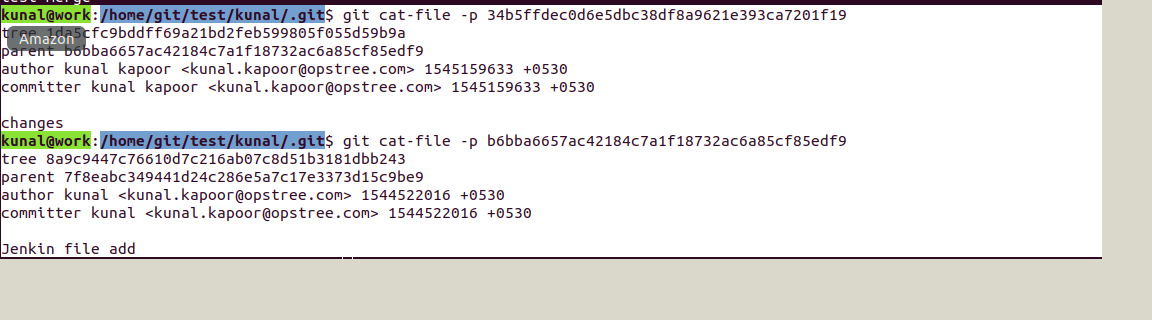
Now we can see a tree object inside the tree object. Further, we can see the details for the tree object which in turn contains a blob object as below:
Below is the pictorial representation for the same:

|
| More elaborated representation for the same : |
Below are the commands for checking the content, type and size of objects( blob, tree and commit)
kunal@work:/home/git/test/kunal# cat README.md
hello
We can find the details of objects( size,type,content) with the help of #git cat-file
git-cat-file:- Provide content, type or size information for repository objects
You an verify the content of commit object and its type with git cat-file as below:
kunal@work:/home/git/test/kunal/.git # cat logs/refs/heads/master
Checking the content of a blob object(README.md, kunal and sandy)
As we can see first one is adding read me , so it is giving null parent(00000…000) and its unique SHA-1 is 912a4e85afac3b737797b5a09387a68afad816d6
Below are the details that we can fetch from above SHA-1 with the help of git cat-file :
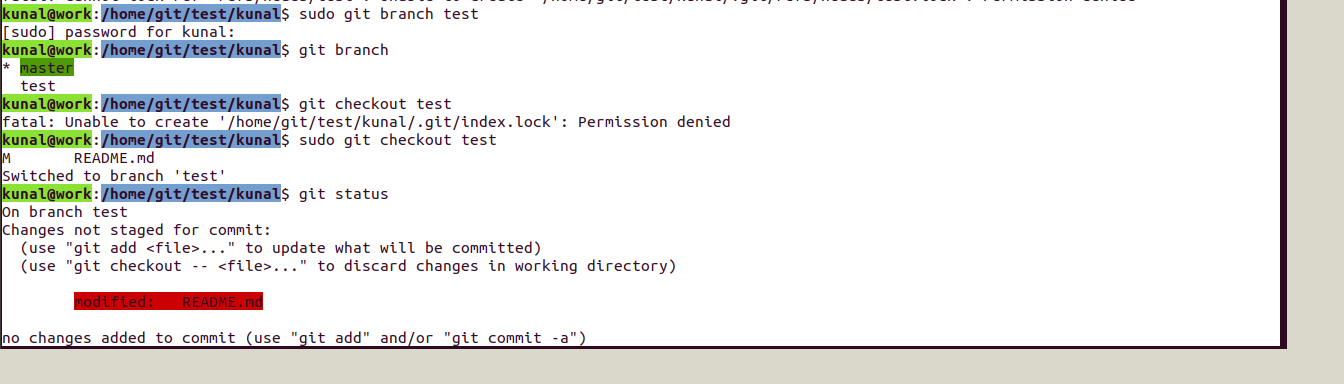
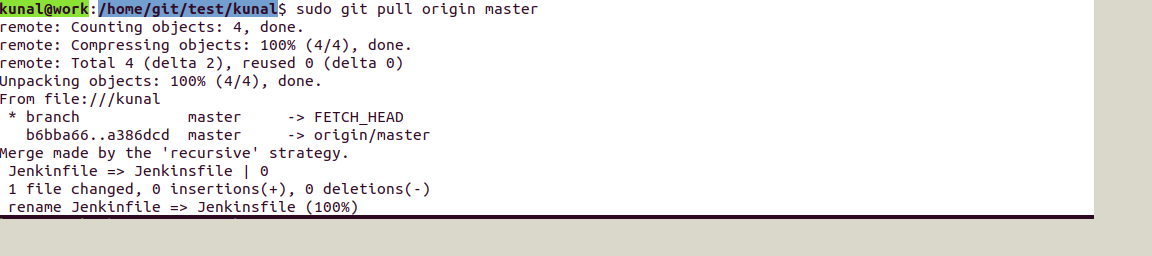
Consider one example of merge:
Created a test branch and made changes and merged it to master.
Here you can notice we have two parents because of a merge request

You can further see the content, size, type of repository #gitobjects like:
Summary
This is pretty lengthy article but I’ve tried to make it as transparent and clear as possible. Once you work through the article and understand all concepts I showed here you will be able to work with Git more effectively.
This explanation gives the details regarding tree data structure and internal storage of objects. You can check the content (differences/commits)of the files through local .git repository which stores each object with unique SHA hash. This would clear basically the internal working of git.
Hopefully, this blog would help you in understanding the git inside out and helps in troubleshooting things related to git.