

Logging and monitoring are like Tony Stark and his Iron Man suit, the two will go together. Similarly, logging and monitoring work best together because they complement each other well.
A blog site on our Real life experiences with various phases of DevOps starting from VCS, Build & Release, CI/CD, Cloud, Monitoring, Containerization.
Logging and monitoring are like Tony Stark and his Iron Man suit, the two will go together. Similarly, logging and monitoring work best together because they complement each other well.
Watching cluster sharding and failover management is as gripping as visualizing a robotic machinery work.
My last blog on Redis Cluster was primarily focussed on its related concepts and requirements. I would highly recommend to go through the concepts first to have better understanding.
Here, I will straight forward move to its setup along with the behaviour of cluster when I intentionally turned down one Redis service on one of the node.
Let’s start from the scratch.
Continue reading “Redis Cluster: Setup, Sharding and Failover Testing”
Recently I was working on a project which includes Terraform and AWS stuff. While working on that I was using my local machine for terraform code testing and luckily everything was going fine. But when we actually want to test it for the production environment we got some issues there. Then, as usual, we started to dig into the issue and finally, we got the issue which was quite a silly one 😜. The production server Terraform version and my local development server Terraform version was not the same.
After wasting quite a time on this issue, I decided to come up with a solution so this will never happen again.
But before jumping to the solution, let’s think is this problem was only related to Terraform or do we have faced the similar kind of issue in other scenarios as well.
Well, I guess we face a similar kind of issue in other scenarios as well. Let’s talk about some of the scenario’s first.
Suppose you have to create a CI pipeline for a project and that too with code re-usability. Now pipeline is ready and it is working fine in your project and then after some time, you have to implement the same kind of pipeline for the different project. Now you can use the same code but you don’t know the exact version of tools which you were using with CI pipeline. This will lead you to error elevation.
Let’s take another example, suppose you are developing something in any of the programming languages. Surely that utility or program will have some dependencies as well. While installing those dependencies on the local system, it can corrupt your complete system or package manager for dependency management. A decent example is Pip which is a dependency manager of Python😉.
These are some example scenarios which we have faced actually and based on that we got the motivation for writing this blog.
To resolve all this problem we just need one thing i.e. containers. I can also say docker as well but container and docker are two different things.
But yes for container management we use docker.
So let’s go back to our first problem the terraform one. If we have to solve that problem there are multiple ways to solve this. But we tried it to solve this using Docker.
As Docker says
Build Once and Run Anywhere
So based on this statement what we did, we created a Dockerfile for required Terraform version and stored it alongside with the code. Basically our Dockerfile looks like this:-
FROM alpine:3.8
MAINTAINER OpsTree.com
ENV TERRAFORM_VERSION=0.11.10
ARG BASE_URL=https://releases.hashicorp.com/terraform
RUN apk add --no-cache curl unzip bash \
&& curl -fsSL -o /tmp/terraform.zip ${BASE_URL}/${TERRAFORM_VERSION}/terraform_${TERRAFORM_VERSION}_linux_amd64.zip \
&& unzip /tmp/terraform.zip -d /usr/bin/
WORKDIR /opstree/terraform
USER opstree
In this Dockerfile, we are defining the version of Terraform which needs to run the code.
In a similar fashion, all other above listed problem can be solved using Docker. We just have to create a Dockerfile with exact dependencies which are needed and that same file can work in various environments and projects.
To take it to the next level you can also dump a Makefile as well to make everyone life easier. For example:-
IMAGE_TAG=latest
build-image:
docker build -t opstree/terraform:${IMAGE_TAG} -f Dockerfile .
run-container:
docker run -itd --name terraform -v ~/.ssh:/root/.ssh/ -v ~/.aws:/root/.aws -v ${PWD}:/opstree/terraform opstree/terraform:${IMAGE_TAG}
plan-infra:
docker exec -t terraform bash -c "terraform plan"
create-infra:
docker exec -t terraform bash -c "terraform apply -auto-approve"
destroy-infra:
docker exec -t terraform bash -c "terraform destroy -auto-approve"
And trust me after making this utility available the reactions of the people who will be using this utility will be something like this:-

Now I am assuming you guys will also try to simulate the Docker in multiple scenarios as much as possible.
There are a few more scenarios which yet to be explored to enhance the use of Docker if you find that before I do, please let me know.
Thanks for reading, I’d really appreciate any and all feedback, please leave your comment below if you guys have any feedback.
Cheers till the next time.
For those who have surfed straight to this blog, please check out the previous part of this series Unix File Tree Part-1 and those who have stayed tuned for this part, welcome back.In the previous part, we discussed the philosophy and the need for file tree. In this part, we will dive deep into the significance of each directory.
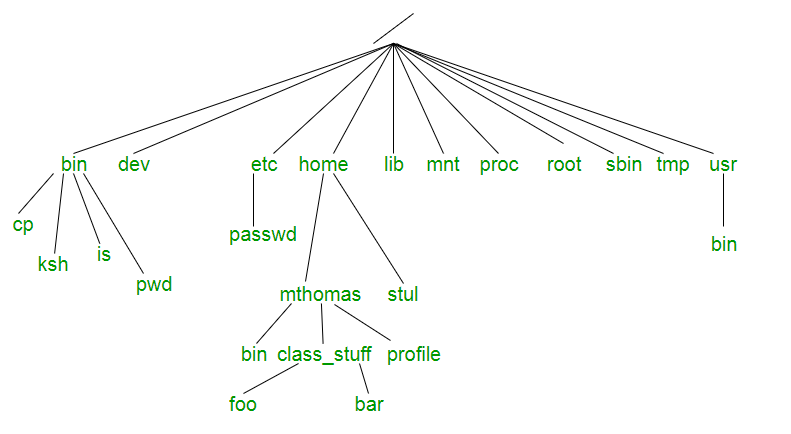
Dayum!! that’s a lot of stuff to gulp at once, we’ll kick out things one after the other.
Let’s talk about the crucial directories which play a major role.
We’ll be discussing those directories which confuse us always, which have almost a similar purpose but still are in separate locations and when asked about them we go like ummmm…….
/bin vs /usr/bin vs /sbin vs /usr/local/bin
This might get almost clear out when I explained the significance of /usr in the above paragraph. Since Unix designers planned /usr to be the local directories of individual users so it contained all of the sub-directories like /usr/bin, /usr/sbin, /usr/local/bin. But the question remains the same how the content is different?
/usr/bin:
/usr/sbin:
I hope I have covered most of the directories which you might come across frequently and your questions must have been answered.
Now that we know about the significance of each UNIX directory, It’s time to use them wisely the way they are supposed to be.
Please feel free to reach me out for any suggestions.
Goodbye till next time!
MITOGEN
In the previous post, we discussed various ways to reduce the ansible-playbook execution time, those changes were mostly made in the ansible config file, by adding or adjusting certain parameters in the file. But as you may have noticed that those methods were not that effective in certain cases, while using those methods we have to be very cautious about the result as they may affect ansible performance in one way or the other.
Generally,
for the slower ansible execution, the main culprit is the way ansible
is executed on the hosts. It creates multiple SSH connections and does
not fully utilize the available resources. To tackle this problem,
MITOGEN came to rescue !!!
Mitogen is a distributed programming library for Python. The Mitogen extension is a set of plug-ins for Ansible that enable it to operate via Mitogen, vastly improving its performance and enhancing its functional capability.
We all know about the strategies in ansible – linear, free & debug., the mitogen is just defined in the strategy column of the config file, so it is just a strategy, we are not making any other changes in the config file of the ansible so it is not affecting any other parameter, it is just the way, playbooks will be executed on the hosts.
Now coming to the mitogen installation part, we just have to download this package at a particular location and make some changes in the ansible config file as shown below,
[defaults]
strategy_plugins = /path/to/mitogen/ansible_mitogen/plugins/strategystrategy = mitogen_linear
we have to define the path where we have stored our mitogen files, and mention the strategy as “mitogen_linear”, under the default section of the config file, and we are good to go.
Now, after the Mitogen installation part, when we run our playbook, we will notice a reasonable reduction in the execution time,
Mitogen is fast because of the following reasons,
All the above-mentioned features make the ansible to run faster.
Mitogen is another extension for ansible that provides a decrease in its execution time and it is very easy to use, I think MITOGEN is very underrated and one of its kind, and we should definitely give it a try.
I hope I have explained everything well, any suggestion/queries are highly appreciated.
Thanks !!!
https://mitogen.networkgenomics.com/ansible_detailed.html