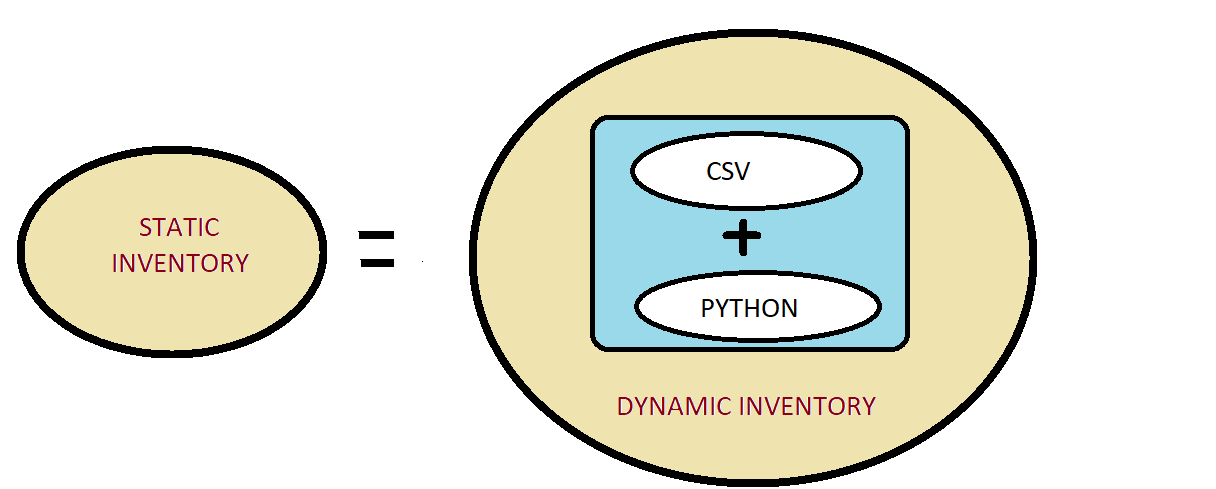
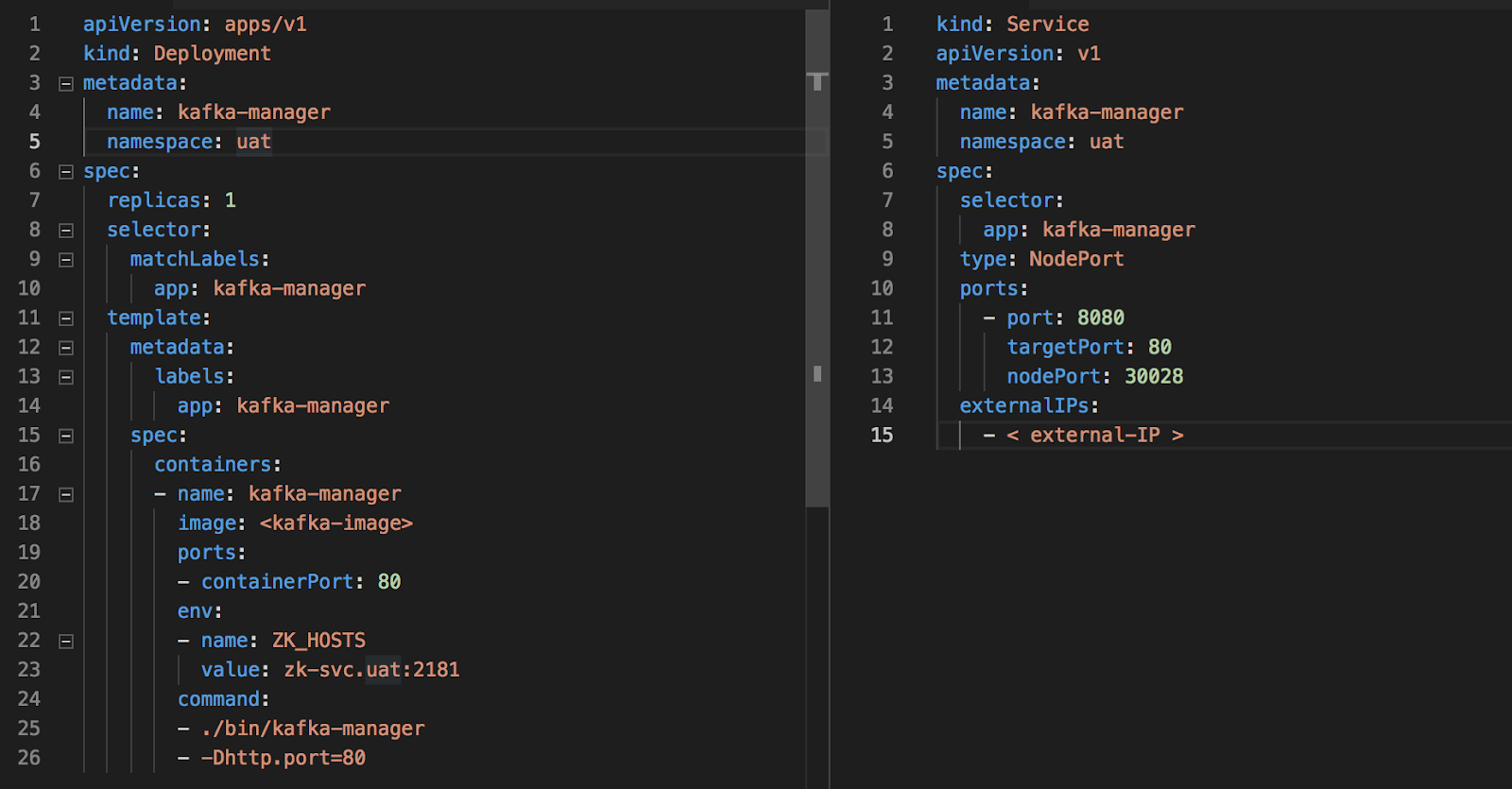
The knowledge of one of the SCM tools is a must for any DevOps engineer, ANSIBLE is one of the popular tools in this category, we all are aware of the ease that Ansible provides whether it is infra provisioning, orchestration or application deployment.
The reason for the vast popularity of Ansible is the long list of modules it provides to support any level of automation, moreover it also gives users the flexibility to create their own modules as per their requirement.
But The purpose of this blog is not to mention the features that ansible provides, but to show how we can speed up our playbook execution in Ansible, as a beginner executing ansible, is very easy and it also feels like saving a lot of time with it, but as you dive deep into it, you will come to know that running ansible playbooks will engage you for a considerable amount of time.
There are a lot of articles available on the internet on how we can speed up our ansible execution, so I have decided to sum up those articles into my blog, with the following methods, we can reduce our execution time without compromising with the overall performance of Ansible.
Before starting, I request you guys to make a small change in your ansible configuration file (ansible.cfg), this small change will help you in tracking the time it will take for the playbook execution, and it also lists out the time is taken by each task.
Just add these lines to your ansible.cfg file under default section,
[default]
callback_whitelist = profile_tasks
Forks
When you are running your playbooks on various hosts, then you may have noticed that the number of servers where the playbook executes simultaneously is 5. You can increase this number inside the ansible.cfg file:
# ansible.cfg
forks = 10
or with a command line argument to ansible-playbook with the -f or –forks options. We can increase or decrease this value as per our requirement.
while using forks we should use “local_action” or “delegated” steps limited in number, as with higher fork value it will affect the ansible-server’s performance.
Async
In ansible, each task blocks the playbook, meaning the connections stay open until the task is done on each node, which is some cases takes a lot of time, here we can use “async” for those particular tasks, with the help of this ansible will automatically move to another task without waiting for the task execution on each node.
To launch a task asynchronously, we need to specify its maximum runtime and how frequently we would like to poll for status, it’s default value in 10 sec.
tasks:
– name: “name of the task”
command: “command we want to execute”
async: 40
poll: 15
The only condition is that the subsequent tasks must not have a dependency on this task.
Free Strategy
When running Ansible playbooks, you might have noticed that the Ansible runs every task on each node one by one, it will not move to another task until a particular task is completed on each node, which will take a lot of time, in some cases.
By default, the strategy is set to “linear”, we can set it to free.
—
– hosts: “hosts/groups”
name: “name of the playbook”
strategy: free
It will run the playbook on each host independently, without waiting for each node to complete.
Facts gathering is the default feature while executing playbook, sometimes we don’t need it.
In those cases, we can disable facts gathering, This has advantages in scaling Ansible in push mode with very large numbers of systems.
—
– hosts: “hosts/groups”
name: “name of the playbook”
gather_facts: no
Pipelining
For each task in Ansible, there are lots of ssh connection created, which results in increasing the total execution time. Pipelining reduces the number of ssh operations required to execute a module by executing many Ansible modules without an actual file transfer. We just have to make these changes in the ansible.cfg file,
# ansible.cfg Pipelining = True
Although this can result in a very significant performance improvement when enabled, Pipelining is disabled by default because requiretty is enabled by default for many distros.
Poll Interval
When we run any the task in Ansible,
it starts polling to check if the task is completed on the host or not, we can
decrease this polling interval time in ansible.cfg to increase its performance,
but it will increase the CPU usage, so we need to adjust its value accordingly
We just have to adjust this the parameter in the ansible.cfg file,
internal_poll_interval=0.001
so, these are the
various ways to decrease our playbook execution time in Ansible, generally we
don’t use all these methods in a single setup, we use these features as per the
requirement,
The
main motive of writing this blog is to determine the factors which will help in
fine-tuning the Ansible performance, and there are many more factors which
serves the same purpose but here I am mentioning the most important parameters
among them.
I hope
I have covered all the important aspects of the blog, feel free to provide your
valuable feedback.
Thanks !!!
Source:
https://mitogen.networkgenomics.com/ansible_detailed.html