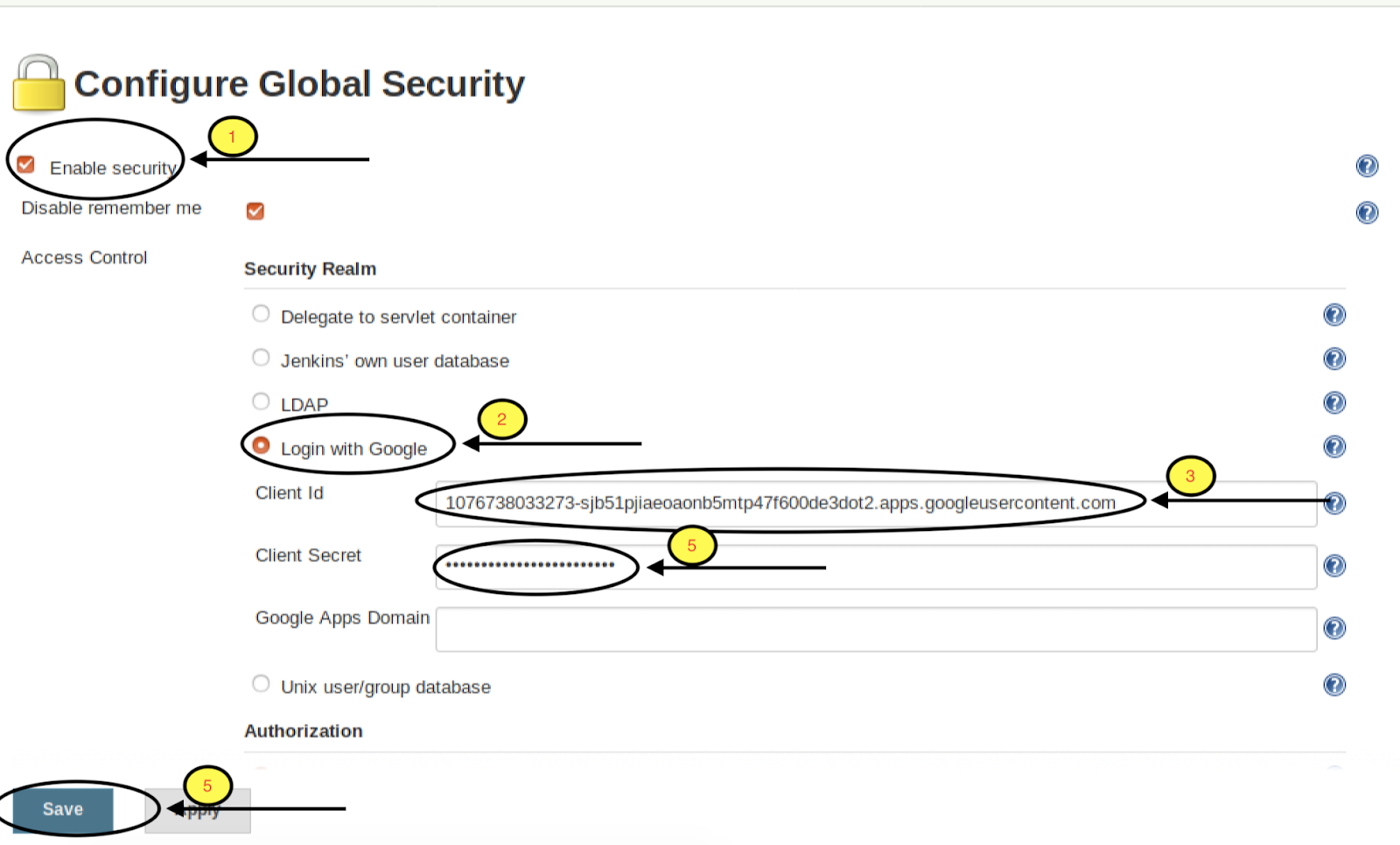
Store, Search And Analyse!
Scenario
The first thing which comes in mind when I hear about logging solutions in my infrastructure is ELK (Elasticsearch, Logstash, Kibana).
But, what happens when logs face an upsurge in the quantity and hamper performance, which, in Elasticsearch words, we may also call “A Fall Back”
We need to get control of situation, and optimize our setup. For which, we require a need for tuning the Elasticsearch
What Is ElasticSearch?
It is a java based, open-source project build over Apache Lucene and released under the license of Apache. It has the ability to store, search and analyse document files in diverse format.
A Bit Of History

Shay Banon was the founder of compass project, thought of need to create a scalable search engine which could support other languages than java.
Therefore, he started to build a whole new project which was the 3rd version of compass using JSON and HTTP interface. The first version of which was released in 2010.
ElasticSearch Cluster
Elasticsearch is a java based project which runs on Java Virtual Machines, wherein each JVM server is considered to be an elasticsearch node. In order to support scalability, elasticsearch holds up the concept of cluster in which multiple nodes runs on one or more host machines which can be grouped together into a cluster which has a unique name.
These clustered nodes holds up the entire data in the form of documents and provides the functionality of indexing and search of those documents.
Types Of Nodes:-
- Master Eligible-Node
Masters are meant for cluster/admin operations like allocation, state maintenance, index/alias creation, etc
- Data Node
Data nodes hold data and perform data-related operations such as CRUD, search, and aggregations.
- Ingest Node
Ingest nodes are able to apply an ingest pipeline to a document in order to transform and enrich the document before indexing.
- Tribe Node
It is a special type of coordinating node that can connect to multiple clusters and perform search and other operations across all connected clusters.
Shards and Replicas
- Shards: Further dividing index into multiple entities are called shards
- Replicas: Making one or more copies of the index’s shards called as replica shards or simple replicas
By default in Elasticsearch every index is allocated with 5 primary shards and single replica of each shard. That means for every index there will be 5 primary shards and replication of each will result in total of 10 shards per index.

Types Of Tuning in ElasticSearch:-
Index Performance Tuning
- Use Bulk Requests
- Use multiple workers/threads to send data to Elasticsearch
- Unset or increase the refresh interval
- Disable refresh and replicas for initial loads
- Disable swapping
- Give memory to the file-system cache
- Use faster hardware
- Indexing buffer size ( Increase the size of the indexing buffer – JAVA Heap Size )
Search Performance Tuning
- Give memory to the file-system cache
- Use faster hardware
- Document modeling (documents should not be joined)
- Search as few fields as possible
- Pre-index data (give values to your search)
- Shards might help with throughput, but not always
- Use index sorting to speed up conjunctions
- Warm up the file-system cache (index.store.preload)
Why Is ElasticSearch Tuning Required?
Elasticsearch gives you moderate performance for search and injection of logs maintaining a balance. But when the service utilization or service count within the infrastructure grows, logs grow in similar proportion. One could easily scale the cluster vertically, but that would increase the cost.
Instead, you can tune the cluster as per the requirement(Search or Injection) while maintaining the cost constrains.
Tune-up
How to handle 20k logs ingestion per sec?
For such high data volume ingestion into elastic search cluster, you would be somehow compromising the search performance.Starting step is to choose the right compute system for the requirement, prefer high compute for memory over CPU. We are using m5.2xlarge(8 CPU/32 GB) as data nodes and t3.medium (2 CPU/ 4 GB) for master.
Elasticsearch Cluster Size
Master – 3 (HA – To avoid the split-brain problem) or 1 (NON-HA)
Data Node – 2
Configure JVM
The optimal or minimal configuration for JVM heap size for the cluster is 50% of the memory of the server.
File: jvm.option
Path: /etc/elasticsearch/
- Xms16g
- Xmx16g
Update system file size and descriptors
- ES_HEAP_SIZE=16g
- MAX_OPEN_FILES=99999
- MAX_LOCKED_MEMORY=unlimited
Dynamic APIs for tuning index performance
With respect to the index tuning performance parameters, below mentioned are the dynamic APIs (Zero downtime configuration update) for tuning the parameters.
Updating Translog
Translog is included in every shard which maintains the persistence of every log by recording every non-committed index operation.
Changes that happen after one commit and before another will be lost in the event of process exit or hardware failure.
To prevent this data loss, each shard has a transaction log or write-ahead log associated with it. Any index or delete operation is written to the translog after being processed by the internal Lucene index.
async – In the event of hardware failure, all acknowledged writes since the last automatic commit will be discarded.
Setting translog to async will increase the index write performance, but do not guarantee data recovery in case of hardware failure.
curl -H "Content-Type: application/json" -XPUT "localhost:9200/_all/_settings?timeout=180s" -d '
{
"index.translog.durability" : "async"
}'
Timeout
Adjust the time period of operation with respect to the number of indexes. Larger number of indexes, higher would be the timeout value.
Number of Replicas to minimal
In case there is a requirement of ingestion of data in large amount (same scenario as we have), we should set the replica to ‘0‘. This is risky as loss of any shard will cause a data loss as no replica set exist for it. But also at the same time index performance will significantly increase as the document has to be index just once, without replica.
After you are done with the load ingestion, you can revert back the same setting.
curl -H "Content-Type: application/json" -XPUT "localhost:9200/_all/_settings?timeout=180s" -d '
{
"number_of_replicas": 0
}'
Increase the Refresh Interval
Making the indexes available for search is the operation called as refresh, and that’s a costly operation in terms of resources. Calling it too frequently can compromise the index write performance.
The Default settings for elasticsearch is to refresh the indexes every second for which the the search request is consecutive in the last 30 seconds.
This is the most appropriate configuration if you have no or very little search traffic and want to optimize for indexing speed.
In case, if your index participate in frequent search requests, in this scenario Elasticsearch will refresh the index every second. If you can bear the expense to increase the amount of time between when a document gets indexed and when it becomes visible, increasing the index.refresh_interval to a grater value, e.g. 300s(5 mins), might help improve indexing performance.
curl -H "Content-Type: application/json" -XPUT 'localhost:9200/_all/_settings?timeout=180s' -d
'{"index" :
{ "refresh_interval" : "300s" }
}'
Decreasing number of shards
Changing the number of shards can be achieved by _shrink and _split APIs. As the name suggests, to increase the number of shards split can be used and shrink for decrease.
By default in Elasticsearch every index is allocated with 5 primary shards and single replica of each shard. That means for every index there will be 5 primary shards and replication of each will result in total of 10 shards per index.
curl -H "Content-Type: application/json" -XPUT "localhost:9200/_all/_settings?timeout=180s" -d '
{
"number_of_shards": 1
}'
When Logstash is Input
Logstash provides the following configurable options for tuning pipeline performance:
- Pipeline Workers
- Pipeline Batch Size
- Pipeline Batch Delay
- Profiling the Heap
Configuring the above parameters would help in increasing the injection rate (index performance), as the above parameters work for feeding in elasticsearch.
Summary
ElasticSearch tuning is very complex and critical task as it can give some serious damage to your cluster or break down the whole. So be careful while modifying any parameters on production environment.
ElasticSearch tuning can be extensively used to add values to the logging system, also meeting the cost constrains.
Happy Searching!
References: https://www.elastic.co
Image References: https://docs.bonsai.io/article/122-shard-primer https://innerlives.org/2018/10/15/image-magic-drawing-the-history-of-sorcery-ritual-and-witchcraft/