
Read more on the advantages of Microservices here! Take a look!
The tech world has always been churning out new concepts and buzzwords every now and then. Here, in this blog, I’d like to talk about a buzzword that has been popular for a while now- Microservices, what Microservices is and the advantages of Microservices implementation.
“Disaggregation” — the idea of segregating functions like computing, storage, and networking to drive organizational efficiency and agility. While the idea of division isn’t entirely new, it is with respect to software development. The notion is best represented by the term Microservices today!
Wondering about the fact what Microservices are? So, here you go! Microservices are modular components that can be deployed independently for improving the agility of software development processes. The benefits of implementing and architecting Microservices Microservices are numerous, including but not limited to better scalability, faster deployment, and improved maintenance.
The process of architecting Microservices can be seen as being adopted by businesses in almost everything around us. I’m sure you’ve probably interacted with a microservice and still didn’t know about it. Do you have a Netflix subscription? Do you buy stuff on Amazon.com or use PayPal? Microservices are a crucial part of all these things.
Companies, at present, are facing intense competitive pressures of delivering the best to their end-users. This relentless pressure and the extraordinary advantages of Microservicesis what continues to drive the adoption of microservices architecture in software development. Here are 3 main reasons how enterprises are leveraging microservices to transform business applications these days.
1. Adapt to Changes
A large monolithic-designed application is not highly adaptable to changes, particularly for unanticipated changes. In today’s ultra-competitive business environment, where everything keeps changing at a lightning speed, we need a technology ecosystem that can easily adapt to changes. This is why all businesses need to know what Microservices are and how they can help. Being a collection of small, independent processes, a microservices-designed application is best suited to adapt to such constant changes taking place in the disruptive market space.
2. Scalability
One of the major advantages of Microservices is improved scalability. The need to scale an application is definitely a tough task when it comes to handling monolithic applications. Since the application is built as one integral whole, there is no option but to scale the entire application, when only a part of the application is required to be scaled. Things are not the same in a microservices architecture wherein each application consists of many modules. So, each module can be scaled independently allowing efficient use of resources and controlled handling of operations. You can easily deploy the updates as it’s much easier and safer to update little parts of an application than to update one big monolithic application.
3. Flexibility
While deploying an application, you might need one of the business modules of your application to be in Java and another in PHP. Different business models need to be designed depending on the technology that is being used. With a microservices architecture, each module of an application is an independent standalone unit and can be designed using whatever parameters are best for that single module. This enables quick adoption of new technologies and allows you to work with the latest technologies combining the “best of the best” components.
Wrapping It All
Microservices are enabling this revolution by delivering improved scalability, enhanced flexibility, high availability, and orchestration services that monolithic software design can’t measure up to. So, it wouldn’t be wrong to say that Microservices has changed the way businesses operate now and therefore architecting Microservices has become a preferred choice for most businesses now.
The incredible advantages of Microservices such as flexibility, easy product management, quick delivery, and faster deployment allow businesses to increase their productivity. This is the reason why the tech community and industry experts are deeply interested in knowing what Microservices are and how they can transform the technology world.
But, there are some disadvantages to employing and architecting Microservices. Difficulties faced while debugging defects and managing the coordination between microservices are some of these. It becomes quite cumbersome and challenging for software teams to manage such complicated and large groups of Microservices.
Realizing this issue(and many others that are faced while delivering a microservices application), we built a single, standardized, comprehensive Microservices Delivery platform — BuildPiper!
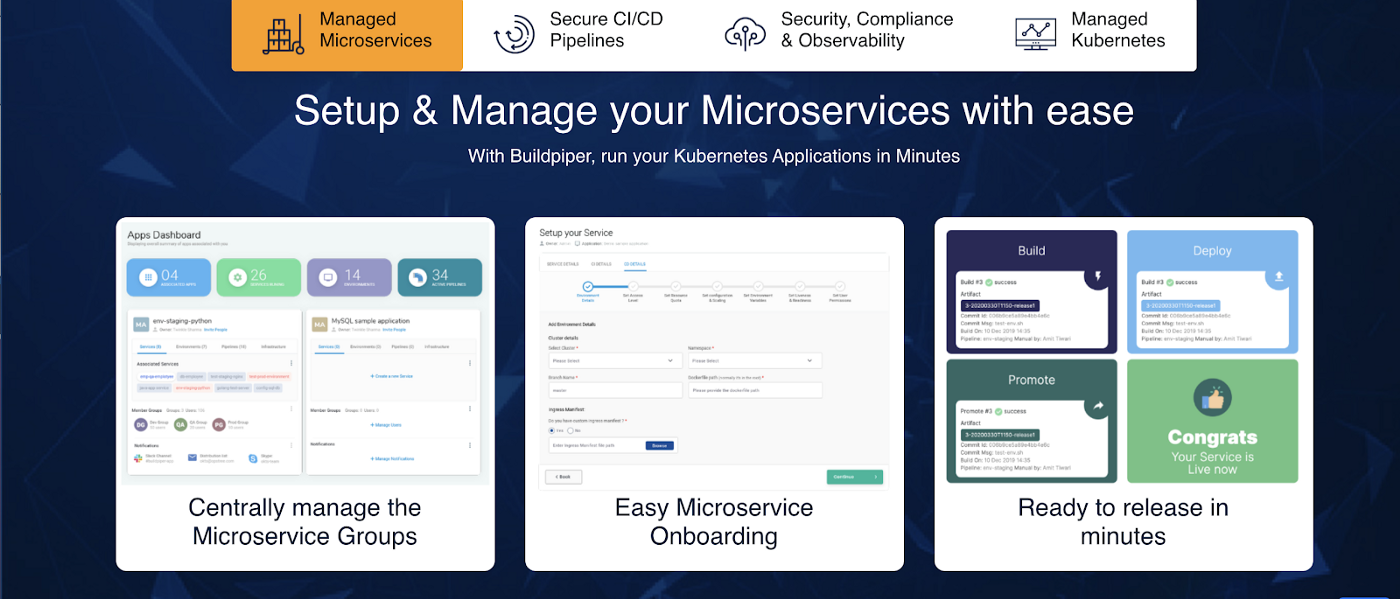
Buildpiper brings along a comprehensive solution for seamless and intuitive microservices delivery with onboarding, environment provisioning, security, Macro & Micro CI-CD pipelines, monitoring, and much more! With its incredible ability to enable production-ready Microservices on Day 1, Buildpiper helps in deploying services in a hassle-free manner. It helps software teams in easy and controlled handling of services thus saving huge time and costs associated to take your product to the market!
Try or schedule a demo today to kick start your Microservices app delivery journey!
Opstree is an End to End DevOps solution provider
Connect Us