Today an issue reported to me that website of our client was loading very slow which was hosted on AWS Windows server and the same website was loading fine when accessed from outside AWS network,I just felt like might be a regular issue but it all together took me to an inside out of the network troubleshooting.
Initially, we checked for SSL certificate expiry, which was not the case, so below are the Two steps which we used to troubleshoot the issue:
Troubleshooting through Browser via Web developer Network tool
In browser we checked which part of code was taking time to load using Network option in developer tools:
- Select web developer tools in firefox
- Then select network
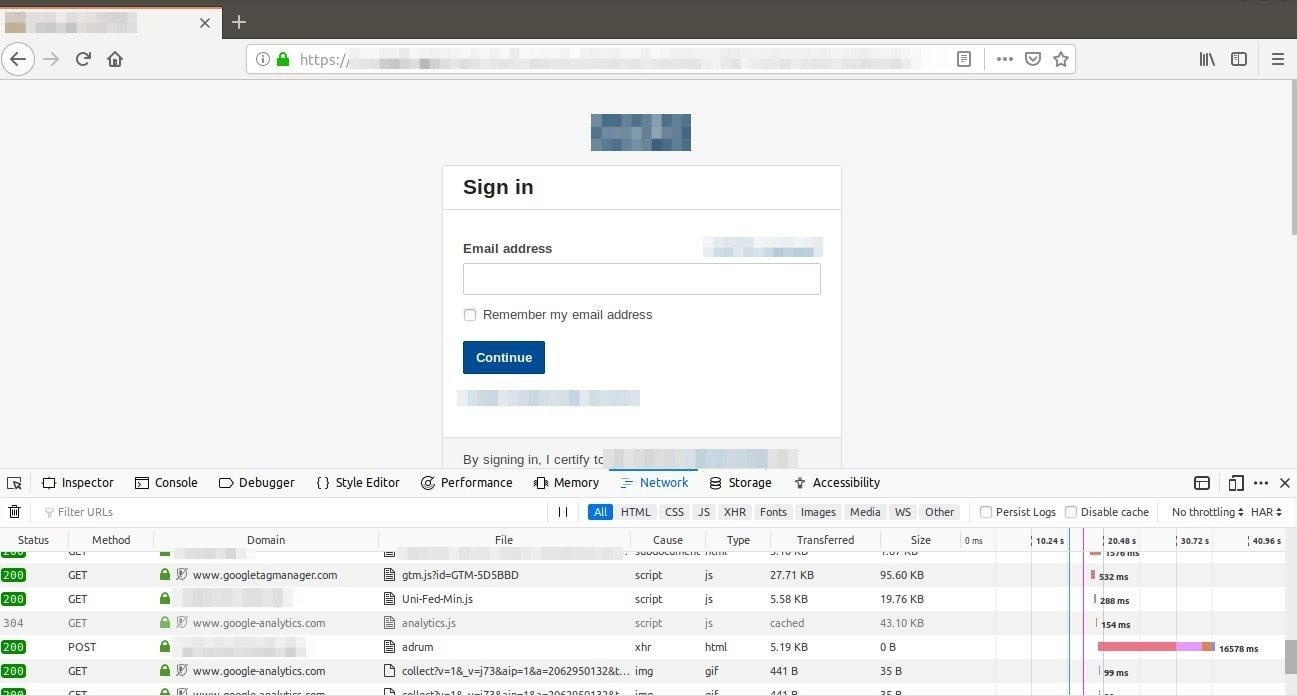
We identified one of the GET calls was taking time to load.
Then when this thing was reported to AWS support team they provided further analysis of this. We can save the report as (.HAR) file which tells us below things:
- How long it takes to fetch DNS information
- How long each object takes to be requested
- How long it takes to connect to the server
- How long it takes to transfer assets from the server to the browser of each object.
Troubleshooting using Traceroute
Then we tried to troubleshoot the AWS network flow using “tracert ” with below output:
Tracing route to example.gov [151.x.x.x] over a maximum of 15 hops:
1 <1 ms <1 ms <1 ms 10.x.x.x
2 * * * Request timed out.
3 * * * Request timed out.
4 * * * Request timed out.
5 * * * Request timed out.
6 * * * Request timed out.
7 <1 ms <1 ms <1 ms 100.x.x.x
8 <1 ms <1 ms 1 ms 52.x.x.x
9 * * * Request timed out.
10 2 ms 1 ms 1 ms example.net [67.x.x.x]
11 2 ms 2 ms 2 ms example.net [67.x.x.x]
12 2 ms 2 ms 2 ms example.net [205.x.x.x]
13 3 ms 3 ms 2 ms 63.x.x.x
14 3 ms 3 ms 3 ms 198.x.x.x
15 4 ms 4 ms 4 ms example.net [63.x.x.x]
And when this was reported to AWS team that RTO from 2-6 we were getting was due to connectivity with internal AWS network which needs to be byepass and was not an issue as packet still reached the next server within 1ms.
Traceroute gives an insight to your network problem.
- The entire path that a packet travels through
- Names and identity of routers and devices in your path
- Network Latency or more specifically the time taken to send and receive data to each devices on the path.
Solution provided by AWS Team
After all the Razzle-Dazzle they just refreshed the network from their end and there was no more website latency after that while accessing from AWS internal network.
Tool recommended by AWS Support team for Network troubleshooting if the issue arises in future:
Wireshark along with .har file using network in web-developer tools from browser.
Wireshark is a network packet analyzer. A network packet analyzer will try to capture network packets and tries to display that packet data as detailed as possible.
You could think of a network packet analyzer as a measuring device used to examine what’s going on inside a network cable, just like a voltmeter is used by an electrician to examine what’s going on inside an electric cable (but at a higher level, of course).
In the past, such tools were either very expensive, proprietary, or both. However, with the advent of Wireshark, all that has changed.
Wireshark is perhaps one of the best open source packet analyzers available today.
Features
The following are some of the many features Wireshark provides:
- Available for UNIX and Windows.
- Capture live packet data from a network interface.
- Open files containing packet data captured with tcpdump/WinDump, Wireshark, and a number of other packet capture programs.
- Import packets from text files containing hex dumps of packet data.
- Display packets with very detailed protocol information.
- Save packet data captured.
- Export some or all packets in a number of capture file formats.
- Filter packets on many criteria.
- Search for packets on many criteria.
- Colorize packet display based on filters.
- Create various statistics.
… and a lot more!